|
|
| Zeile 255: |
Zeile 255: |
| == Wiederholungsaufgaben/Übungen == | | == Wiederholungsaufgaben/Übungen == |
|
| |
|
| '''4.4.1 Was ist der Unterschied zwischen Identifikation, Authentifikation und Autorisation?''' | | '''1 Was ist der Unterschied zwischen Identifikation, Authentifikation und Autorisation?''' |
|
| |
|
| '''4.4.2 Was ist eine Zwei-Faktor-Authentifikation?''' | | '''2 Was ist eine Zwei-Faktor-Authentifikation?''' |
|
| |
|
| '''4.4.3 Welche drei Zugriffssteuerungsmodelle gibt es?''' | | '''3 Welche drei Zugriffssteuerungsmodelle gibt es?''' |
|
| |
|
| '''4.4.4 Erklären Sie das Modell der Eigner-definierten Zugriffssteuerung.''' | | '''4 Erklären Sie das Modell der Eigner-definierten Zugriffssteuerung.''' |
|
| |
|
| '''4.4.5 Was sind Zertifikate und die damit verbundenen Vertrauensmodelle?''' | | '''5 Was sind Zertifikate und die damit verbundenen Vertrauensmodelle?''' |
|
| |
|
| '''4.4.6 Was bedeutet PKI und wer sind ihre Hauptakteure? Wie hängen diese Akteure zusammen?''' | | '''6 Was bedeutet PKI und wer sind ihre Hauptakteure? Wie hängen diese Akteure zusammen?''' |
|
| |
|
| '''4.4.7 Eine Passwortrichtlinie fordert ein Passwort, bestehend aus Kleinbuchstaben, Großbuchstaben und Ziffern mit einer Länge von 10 Zeichen. Wie wird die Komplexität des Passworts berechnet (wie viele mögliche Passwörter gibt es)?''' | | '''7 Eine Passwortrichtlinie fordert ein Passwort, bestehend aus Kleinbuchstaben, Großbuchstaben und Ziffern mit einer Länge von 10 Zeichen. Wie wird die Komplexität des Passworts berechnet (wie viele mögliche Passwörter gibt es)?''' |
| | |
| = Netzwerksicherheit =
| |
| | |
| Ein wesentlicher Aspekt der technischen Informationssicherheit ist die Netzwerksicherheit. Wenn Daten von einem Gerät zu einem anderen übertragen werden, muss die Einhaltung der Schutzziele (Vertraulichkeit, Integrität und Verfügbarkeit; siehe Lektion 1.3) weiter gewährleistet werden. Eine genaue Betrachtung der Übertragungsverfahren und Zugriffe ist daher unbedingt erforderlich, da aufgrund der standardmäßigen Offenheit der aktuellen Übertragungstechnologien meist auch eine Vielzahl von Angriffsvektoren möglich ist.
| |
| | |
| == Sicherheitsaspekte der Netzwerkschichten ==
| |
| | |
| Die Betrachtung der Netzwerksicherheit bedarf einer gesonderten Betrachtung der einzelnen Netzwerkschichten. In jeder Schicht gibt es eigene Schwachstellen und mögliche Maßnahmen der Absicherung.
| |
| | |
| Ein Überblick der Netzwerkschichten des OSI-Referenzmodells ist in Tabelle 5 aufgelistet. Die Details dazu finden sich im Studienheft IT112 - Netzwerke und verteilte Systeme – von Univ.-Prof. DI Dr. Erich Schikuta, in Lektion 5.
| |
| | |
| <span id="_Ref172306576" class="anchor"></span>Tabelle 5: OSI-Schichten und TCP/IP Modell
| |
| | |
| {| style="border-collapse: collapse;" border="1"
| |
| ! width="4%" | OSI-Modell
| |
| ! width="24%" | <br>
| |
| ! width="16%" | Einordnung
| |
| ! width="33%" | Funktion
| |
| ! width="20%" | TCP/IP-Modell
| |
| |-
| |
| | 7
| |
| | Anwendungsschicht (Application Layer)
| |
| | Anwendungsorientiert
| |
| | Netzwerkschnittstelle zur Anwendung
| |
| | Anwendungs-Schicht
| |
| |-
| |
| | 6
| |
| |
| |
| <br>
| |
| | Darstellungsschicht (Presentation Layer)
| |
| |
| |
| <br>
| |
| | Daten-Repräsentation und Verschlüsselung
| |
| |-
| |
| | 5
| |
| |
| |
| <br>
| |
| | Sitzungsschicht (Session Layer)
| |
| |
| |
| <br>
| |
| | Kommunikation zwischen Rechnern
| |
| |-
| |
| | 4
| |
| | Transportschicht (Transport Layer)
| |
| | Transportorientiert
| |
| | Ende-zu-Ende Verbindungen und Verlässlichkeit
| |
| | Host-zu-Host-Schicht
| |
| |-
| |
| | 3
| |
| |
| |
| <br>
| |
| | Vermittlungsschicht (Network Layer)
| |
| | Pfad Bestimmung und logische Adressierung
| |
| | Internet-Schicht
| |
| |-
| |
| | 2
| |
| |
| |
| <br>
| |
| | Sicherungsschicht (Data Link Layer)
| |
| | Physische Adressierung
| |
| | Netzzugangs-Schicht
| |
| |-
| |
| | 1
| |
| |
| |
| <br>
| |
| | Übertragungsschicht (Physical Layer)
| |
| |
| |
| <br>
| |
| | Medium, Signal und binäre Übertragung
| |
| |}
| |
| Die Absicherung der einzelnen Schichten – zur Erreichung der Schutzziele – erfolgt nun durch den Einsatz der acht spezifischen Sicherheitsmechanismen [Ec09, 737]:
| |
| | |
| * Kryptografische Verfahren,
| |
| * Digitale Signaturen,
| |
| * Zugriffskontrollmechanismen,
| |
| * Datenintegritätsmechanismen,
| |
| * Austausch von Authentizitätsinformationen,
| |
| * Anonymisierung und Verschleierung von Verkehrsdaten,
| |
| * Mechanismen zur Kontrolle der Wegewahl und
| |
| * Notariatsmechanismen.
| |
| | |
| === Transportorientierte Sicherheitsaspekte ===
| |
| | |
| Das Ziel der transportorientierten Netzwerkschichten ist die Übertragung von Daten zwischen zwei Geräten. Dabei ist es meist erforderlich, die Weiterübertragung durch dazwischen liegende Geräte und auch unterschiedliche Übertragungsmedien in Anspruch zu nehmen. Dabei kann es zu Datenverlust und Datenänderungen kommen. Auch muss die Möglichkeit der Abhörung des Datenverkehrs in berücksichtigt werden.
| |
| | |
| Durch manipulierte und fehlerhafte Pakete kann es ebenfalls zu Beeinträchtigungen der beteiligten IT-Systeme kommen. Daher ist es erforderlich die Weiterleitung und Verarbeitung des Netzwerkverkehrs zu limitieren und alle ungewollten Pakete zu filtern.
| |
| | |
| Zur Absicherung des Transports werden in den unteren Schichten meist Firewalls (siehe weiter 5.2) und in den oberen Schichten bestimmte Protokolle eingesetzt. Einige wichtige Absicherungstechnologien auf Protokollebene sind:
| |
| | |
| * TLS (Transport Layer Security),
| |
| * IPsec (Internet Protocol Security),
| |
| * PPTP (Point-to-Point Tunnelling Protocol),
| |
| * L2TP (Layer 2 Tunneling Protocol),
| |
| * PPP (Point-to-Point Protocol),
| |
| * PAP (Password Authentication Protocol),
| |
| * CHAP (Challenge Handshake Authentication Protocol),
| |
| * RADIUS (Remote Authentication Dial-In User Service),
| |
| * DIAMETER (keine Abkürzung; Bezug des Namens zu RADIUS),
| |
| * TACACS+ (Terminal Access Controller Access Control System) und
| |
| * WPA2 (Wi-Fi Protected Access 2).
| |
| Nicht vergessen werden darf dabei auch auf das Übertragungsmedium selbst. So können ungesicherte Netzwerkdosen und schlecht abgesicherte WLAN Verbindungen ein leichtes Eintrittstor in das interne Netzwerk sein. Auch gibt es Möglichkeiten den Netzwerkverkehr über die entstehenden elektromagnetischen Felder der Kabel und beteiligten Geräte abzuhören und natürlich können in der anderen Richtung auch Störungen durch elektromagnetische Felder im Kabelumfeld (z.B. durch Stromleitungen, Motoren oder Generatoren) entstehen.
| |
| | |
| In Tabelle 6 sind die wesentlichen Aufgaben der hier aufgezählten Protokolle, sowie ihre Einordnung in die Netzwerkschichten zusammengefasst.
| |
| | |
| <span id="_Ref415228609" class="anchor"></span>Tabelle : Protokolle der transportorientierten Netzwerkschichten
| |
| | |
| {| style="border-collapse: collapse;" border="1"
| |
| ! width="30%" | Protokoll
| |
| ! width="15%" | Netzwerk-schicht
| |
| ! width="54%" | Zweck
| |
| |-
| |
| | TLS (Transport Layer Security)
| |
| | OSI Layer 4
| |
| | Neue Bezeichnung und Weiterentwicklung von SSL (Secure Socket Layer). Unterstützt Verschlüsselung und Authentifizierung mittels Zertifikaten.
| |
| |-
| |
| | IPsec (Internet Protocol Security)
| |
| | OSI Layer 3
| |
| | Betrieb eines VPN Tunnels (siehe Lektion 5.3).
| |
| |-
| |
| | PPTP (Point-to-Point Tunnelling Protocol)
| |
| | OSI Layer 2
| |
| | Betrieb eines VPN Tunnels (siehe Lektion 5.3).
| |
| |-
| |
| | L2TP (Layer 2 Tunneling Protocol)
| |
| | OSI Layer 2
| |
| | Betrieb eines VPN Tunnels (siehe Lektion 5.3).
| |
| |-
| |
| | PPP (Point-to-Point Protocol)
| |
| | OSI Layer 2
| |
| | Verbindungsaufbau über Einwahlleitungen (Modem). Nutzt PAP oder CHAP zur Authentifikation.
| |
| |-
| |
| | PAP (Password Authentication Protocol)
| |
| | OSI Layer 2
| |
| | Authentifikation über das PPP.<br>
| |
| Passwörter werden unverschlüsselt übertragen.
| |
| |-
| |
| | CHAP (Challenge Handshake Authentication Protocol)
| |
| | OSI Layer 2
| |
| | Authentifikation über das PPP.<br>
| |
| Keine Passwortübertragung, sondern Prüfung durch Hashwerte aus Passwort und gemeinsamer Zufallszahl.
| |
| |-
| |
| | RADIUS (Remote Authentication Dial-In User Service)
| |
| | OSI Layer 2
| |
| | Authentifikation von Clients in Netzwerken.
| |
| |-
| |
| | DIAMETER (keine Abkürzung; Bezug des Namens zu RADIUS)
| |
| | OSI Layer 2
| |
| | Weiterentwicklung von RADIUS mit größerem Funktionsumfang.
| |
| |-
| |
| | TACACS+ (Terminal Access Controller Access Control System)
| |
| | OSI Layer 2
| |
| | Weiterentwicklung von RADIUS mit verschlüsselter Kommunikation.
| |
| |-
| |
| | WPA2 (Wi-Fi Protected Access 2)
| |
| | OSI Layer 2
| |
| | Nachfolger von WEP (Wired Equivalent Privacy) und WPA. Authentifizierung und Verschlüsselung von WLAN-Verbindungen.
| |
| |}
| |
| | |
| === Anwendungsorientierte Sicherheitsaspekte ===
| |
| | |
| Die Absicherung von Netzwerken auf Anwendungsebene geschieht durch Protokolle und ihre Implementierung in den jeweiligen Applikationen. Die häufigsten Anwendungsgebiete sind dabei die sichere Kommunikation mit Webseiten und über E-Mail, sowie der Dateitransfer und Serverzugriff.
| |
| | |
| Für eine sichere Kommunikation zwischen '''Webseiten und Browsern''' wurde das HTTP (Hypertext Transfer Protokoll) Protokoll um die Möglichkeit eines Transportes mittels TLS (Transport Layer Security, vormals SSL) erweitert. Das daraus entstandene '''HTTPS (HTTP over SSL)''' Protokoll kombiniert somit ein Protokoll der Anwendungsschicht mit einem Protokoll der Transportschicht.
| |
| | |
| Durch die Möglichkeiten von TLS, einer verschlüsselten Kommunikation und der zertifikatsbasierten Authentifizierung der Kommunikationspartner, werden sichere Verbindungen zwischen Webserver und Internetbrowser ermöglicht. Je nach Ausprägung wird es nur zur Verschlüsselung, zur Authentifikation des Servers gegenüber dem Client oder sogar zur Authentifikation des Clients gegenüber dem Sever (mittels Clientzertifikat) genutzt.
| |
| | |
| Auch das File Transfer Protokoll (FTP) ist in einer um TLS erweiterten Version '''FTPS (FTP over SSL)''' verfügbar.
| |
| | |
| Sowohl HTTP, als auch FTP übertragen ihre Daten ohne die genannten TLS Erweiterungen gänzlich unverschlüsselt. Die Daten sind in den Ursprungsversionen dieser Protokolle auch nicht vor Manipulationen geschützt.
| |
| | |
| Zur Absicherung von '''E-Mail-Kommunikation''' wurde der E-Mail-Standard MIME (Multipurpose Internet Mail Extensions), welcher den Aufbau von E-Mail-Nachrichten regelt, mit '''S/MIME (Secure MIME)''' um die Möglichkeit zertifikatsbasierter Verschlüsselung und Signierung der Nachrichten erweitert.
| |
| | |
| Um eine sichere Verbindung zu '''Serverkonsolen''' zu ermöglichen, kann das '''Secure Shell (SSH)''' Protokoll eingesetzt werden. Es basiert auf einer zertifikatsbasierten Authentifizierung und Verschlüsselung. Ähnlich wie bei TLS kann diese sowohl über Server-, als auch über Clientzertifikate erfolgen. Die Übertragung der Konsolendaten zwischen Server und Client erfolgt textbasiert. Weiter ist es möglich, Dateien zu übertragen. Diese Protokollform wird dann als '''SFTP (SSH File Transfer Protokoll)''' bezeichnet.
| |
| | |
| == Firewalls ==
| |
| | |
| Der Begriff „Firewall“ kommt von der bildlichen Vorstellung einer brennenden Barriere, welche nicht überwunden werden kann. Eine bessere Darstellung wäre dafür jedoch eher eine mittelalterliche Zugbrücke mit Wachposten, da eine Firewall nicht für alle unüberwindbar sein soll und bestimmte Reisende ungehindert durchlassen muss. Ein weiterer, besserer, Vergleich ist der einer Brandschutzwand mit einer Türe, die zwar alle Personen durchlässt, jedoch das Feuer (unerwünschtes) blockiert.
| |
| | |
| Eine Firewall steht immer zwischen zwei getrennten Teilen eines Computernetzwerks. Sie kontrolliert den gesamten Datenverkehr und lässt nur jene Daten durch, die den vorgegebenen Regeln entsprechen (siehe Abbildung 19).
| |
| | |
| [[Datei:IT244 19.png|300px|none|thumb|Grundprinzip einer Firewall]]
| |
| <span id="_Ref415233550" class="anchor"></span>
| |
| | |
| Eine Firewall kann dabei auf unterschiedlichen Netzwerkschichten aufsetzen und ist meist Teil eines Netzwerkgerätes der jeweiligen Schicht (Bridge, Switch, Router oder Server).
| |
| | |
| Aktuelle Firewall-Lösungen decken inhaltlich meist mehrere Firewall-Typen ab. So sind meist Packet-Filter-Firewalls und Stateful Firewalls kombiniert. Application Level Firewalls sind häufig auch, in Form von Modulen, in die jeweiligen Serverdienste integriert, die sie schützen sollen.
| |
| | |
| Im Bereich der zunehmenden Virtualisierung von Rechnernetzen ist es nötig, eine Absicherung durch virtuelle Netzwerkhardware zu gewährleisten. Dazu gehören auch '''virtualisierte Firewalls''' mit demselben Funktionsumfang.
| |
| | |
| Die unterschiedlichen Typen von Firewalls sind:
| |
| | |
| * Packet Filter Firewalls,
| |
| * Stateful Firewalls,
| |
| * Proxy Firewalls,
| |
| * Circuit-Level Proxy-Firewalls,
| |
| * Application-Level Proxy-Firewalls und
| |
| * Kernel Proxy-Firewalls.
| |
| Bei '''Packet Filter Firewalls''' handelt es sich um die Implementierung von Regeln der '''transportierenden Netzwerkschichten'''. Dabei werden bestimmte Pakettypen und die zugehörigen '''Paketheader''' überprüft. Eine inhaltliche Prüfung der Daten erfolgt hierbei nicht. Über die Paketheader können Daten wie '''Herkunftsadresse''' und '''Zieladresse''', das verwendete '''Transport-Protokoll''', sowie die zugehörigen '''Portnummern''', geprüft werden.
| |
| | |
| Zusätzlich zu den Packet Filter Firewalls werden bei '''Stateful Firewalls''' die Pakete nicht nur einzeln, sondern im Zusammenhang der gesamten zugehörigen Verbindung betrachtet. Das bedeutet, dass der Verbindungsaufbau und die laufende Kommunikation erkannt werden. Dadurch ist es möglich, auf unterschiedliche Phasen einer Netzwerktransaktion unterschiedlich zu reagieren. Auch können ungültige Pakete erkannt werden, die in der aktuellen Phase der jeweiligen Verbindung nicht zulässig sind. Die einzelnen Verbindungen werden dabei in der State-Table der Firewall verwaltet.
| |
| | |
| Bei den '''Proxy-Firewalls''' handelt es sich um Firewalls der '''anwendungsorientierten Schichten'''. Je nach der zugehörigen Schicht untergliedern sie weiter sich in eigene Untertypen.
| |
| | |
| Die '''Circuit-Level Proxy-Firewall''' befindet sich auf Ebene der '''Sitzungsschicht'''. Sie unterstützt Regeln zu einem breiten Spektrum an Anwendungsprotokollen, kann jedoch nicht den Inhalt der Anwendungsschicht überprüfen. Sie prüft lediglich den Header der Pakete der Sitzungsschicht und leitet daraus ab, welche Anwendungskommunikationen stattfinden sollen.
| |
| | |
| Eine detaillierte Analyse des Netzwerkverkehrs ermöglicht hingegen die '''Application-Level Proxy-Firewall'''. Sie befindet sich auf Ebene der '''Anwendungsschicht''' und kann damit den Inhalt des Netzwerkverkehrs auf Anwendungsebene überprüfen. Dies ermöglicht eine Erkennung von unerwünschten Zugriffen auf Anwendungen durch Auswertung der direkten Anwendungskommunikation. Ein Beispiel für eine Application-Level Proxy-Firewall ist ein '''HTTP-Proxy-Server''' mit Content Filterung und Virenschutz. Er kann dabei unerwünschte Webinhalte und Schadcode erkennen und dem Anwender statt diesem eine Fehlermeldung senden.
| |
| | |
| Bei '''Kernel Proxy-Firewalls''' ist die gesamte Funktionalität direkt im Betriebssystem-Kernel implementiert. Sie verarbeiten die Pakete mittels virtueller Netzwerk-Stacks. Das bedeutet, dass für jedes Paket ein individueller virtueller Bereich angelegt wird, in dem dann seine Überprüfung stattfindet. In diesem virtuellen Stack gibt es dann je Netzwerkschicht eigene Regelwerke. Da die gesamte Verarbeitung direkt im Kernel erfolgt, sind Kernel Proxy-Firewalls performanter als Application-Level Proxy-Firewalls.
| |
| | |
| Eine weitere wichtige Funktionalität von Firewalls ist das '''IP-Masquerading''' und die damit verbundene '''Network Address Translation (NAT)'''. Damit wird ermöglicht, eine einzelne öffentliche IP-Adresse durch mehrere Clients mit privaten IP-Adressen zu nutzen. Auch können damit Port-Weiterleitungen von der öffentlichen IP-Adresse zu dahinter liegenden Servern mit privaten IP-Adressen realisiert werden. Die Details zu öffentlichen und privaten IP-Adressen und die Funktionsweise des IP-Masquerading wurden bereits im Studienheft IT112 - Netzwerke und verteilte Systeme – von Univ.-Prof. DI Dr. Erich Schikuta genauer erläutert.
| |
| | |
| Im Zusammenhang mit Firewalls werden oft '''Intrusion Detection Systeme (IDS)''' eingesetzt. Dabei handelt es sich um Dienste, die den gesamten Netzwerkverkehr einer bestimmten Verbindung übermittelt bekommen und diesen analysieren. Sie erkennen dabei mögliche Angriffsmuster und Auffälligkeiten in den Verbindungsinformationen. Sobald ein IDS eine Auffälligkeit erkennt, kann es diese dokumentieren und melden. In bestimmten Fällen kann es auch so konfiguriert werden, dass es neue Firewall-Regeln hinzufügt, die die auffälligen Verbindungen blockiert.
| |
| | |
| Für den Betrieb von Servern, die von außen erreichbar sein sollen (z.B. Webserver und E-Mail-Server), wird meist ein gesondertes Netzwerksegment eingerichtet. Dieses hat dann eigene Firewall-Regeln, welche den Zugriff der Server auf das interne Netzwerksegment stark einschränken. Dadurch wird diese, risikoreichere Zone, von dem internen Netzwerk getrennt und kann auch gesondert überwacht werden. Da hierbei einzelne Zugriffe von außen in diese weniger sichere Zone durchgelassen werden, wird sie als '''De-Militarisierte-Zone (DMZ)''' bezeichnet.
| |
| | |
| == Virtuelle Private Netze (VPN) ==
| |
| | |
| Ein Virtuelles Privates Netz (VPN) dient der Vernetzung mehrerer Standorte über unsichere Datenleitungen (z.B. über das Internet). Dies ist oft erforderlich, wenn ein Unternehmen mehrere Standorte hat, oder wenn Mitarbeiter mobil arbeiten und dabei Zugriff auf das interne Netzwerk benötigen.
| |
| | |
| Bei einem VPN werden die Daten einer kompletten Netzwerkschicht verschlüsselt übertragen. Dies geschieht oft direkt über VPN Dienste, welche in die jeweilige Firewall-Lösung integriert sind. In Abbildung 20 ist eine VPN Verbindung dargestellt, die zwei Bürostandorte über das Internet miteinander verbindet. Das VPN ist dabei auf den Firewalls installiert, die gleichzeitig Gateways ins Internet sind. Die verschlüsselte Verbindung zwischen den beiden VPN-Endpunkten (in diesem Fall die Firewalls) wird als '''VPN-Tunnel''' bezeichnet.
| |
| | |
| [[Datei:IT244 20.png|300px|none|thumb|VPN Verbindung zwischen zwei Standorten]]
| |
| <span id="_Ref415560325" class="anchor"></span>
| |
| | |
| Wenn ein einzelner Computer an ein VPN angebunden ist, wird der VPN Tunnel durch einen lokalen VPN Dienst des Computers an das Unternehmensnetz angebunden. Die lokal installierte Software wird dabei als '''VPN-Client''' und der Einstiegspunkt in das Unternehmensnetz als '''VPN-Gateway''' bezeichnet.
| |
| | |
| Wie der Schlüsseltausch und der Verbindungsaufbau für die gemeinsame Verbindung aussehen und welche Chiffren verwendet werden, hängt vom jeweiligen VPN Protokoll ab. Die meisten Protokolle unterstützen dabei mehrere unterschiedliche Chiffren um mit möglichst vielen Clients kompatibel sein zu können. Hier ist jedoch Vorsicht geboten, da diese großzügige Kompatibilität von Angreifern ausgenutzt werden kann, indem sie versuchen eine Verbindung mit einer möglichst schwachen Chiffre aufzubauen, um diese dann wiederum leichter analysieren zu können. Die verwendeten Chiffren sollten daher im VPN-Gateway sehr genau auf die Anforderungen möglichen VPN-Clients abgestimmt sein. Alle nicht benötigten Methoden sollten dann deaktiviert werden.
| |
| | |
| Der größere Aufwand bei einer VPN Verbindung ist immer der Verbindungsaufbau, da hier die Authentifikation, der Schlüsseltausch (siehe Lektion 3.5) und die Vereinbarung der Chiffre erfolgt. Die Verschlüsselung der Datenleitung erfolgt dann meist über symmetrische Kryptographie-Methoden (siehe Lektion 3.3) und ist daher wesentlich schneller.
| |
| | |
| Dies ist vergleichbar mit dem Graben eines Tunnels. Der Aufbau des Tunnels ist sehr schwierig und dauert lange (Tunnelbohrer, korrekte Bohrstrecke bis zum Endpunkt, Stützen der Tunnelwände,…). Sobald der Tunnel jedoch gegraben ist, kann dieser sehr einfach von beiden Seiten befahren werden.
| |
| | |
| Es gibt eine Vielzahl von VPN-Protokollen auf unterschiedlichen Netzwerkschichten. Einige der wichtigsten Protokolle sind in Tabelle 7 aufgelistet.
| |
| | |
| <span id="_Ref415562340" class="anchor"></span>Tabelle : VPN-Protokolle
| |
| | |
| {|
| |
| ! width="64%" | Protokoll
| |
| ! width="35%" | Netzwerkschicht
| |
| |-
| |
| | PPTP (Point-to-Point Tunneling Protocol)
| |
| | OSI Layer 2
| |
| |-
| |
| | L2TP (Layer 2 Tunneling Protocol)
| |
| | OSI Layer 2
| |
| |-
| |
| | IPsec (Internet Protocol Security)
| |
| | OSI Layer 3
| |
| |-
| |
| | OpenVPN (Open Source VPN)
| |
| | OSI Layer 3
| |
| |-
| |
| | SSTP (Secure Socket Tunneling Protocol)
| |
| | OSI Layer 3
| |
| |}
| |
| | |
| == Web Application Security ==
| |
| | |
| Eine Vielzahl der Angriffe auf IT-Systeme geschieht im Bereich der Webanwendungen. Die Webserver sind meist öffentlich erreichbar und bieten daher eine leicht auffindbare und optimale Angriffsfläche. Oft werden IT-Systeme mit bestimmten Schwachstellen im Web über Suchmaschinen gesucht (Siehe 5.6.4 Google Hacking), um sie dann gezielt angreifen zu können.
| |
| | |
| Das Eintrittstor in den Webserver sind meist die darauf laufenden Webanwendungen. Es ist daher unbedingt erforderlich, bereits bei der Entwicklung der Applikationen auf IT-Sicherheit zu achten und diese in den Entwicklungsprozess mit einzubeziehen. Unsicherer Programmcode ist im Nachhinein nur aufwändig zu entdecken und zu korrigieren.
| |
| | |
| === OWASP Top 10 ===
| |
| | |
| Die Bedrohungen für Web-Applikationen werden regelmäßig in ihrer Häufigkeit erfasst und durch unterschiedliche Stellen ausgewertet. Die bekannteste Auswertung wird durch das OWASP Top Ten Project erstellt. OWASP ist eine Non-Profit-Organisation, deren Ziel es ist, die Erhöhung der Sicherheit von Web-Anwendungen zu fördern.
| |
| | |
| Die derzeitige OWASP Top 10 Liste (Stand 12. Juni 2013) beinhaltet folgende Bedrohungen, absteigend sortiert [Ow15a]:
| |
| | |
| # Injection
| |
| # Broken Authentication and Session Management
| |
| # Cross-Site Scripting (XSS)
| |
| # Insecure Direct Object References
| |
| # Security Misconfiguration
| |
| # Sensitive Data Exposure
| |
| # Missing Function Level Access Control
| |
| # Cross-Site Request Forgery (CSRF)
| |
| # Using Components with Known Vulnerabilities
| |
| # Unvalidated Redirects and Forwards
| |
| Die Top 3 der häufigsten Bedrohungen nach OWASP werden am Ende der Lektion im Rahmen der Angriffsvektoren (5.6) genauer erläutert.
| |
| | |
| === Web Application Firewalls (WAF) ===
| |
| | |
| Oft existieren Anwendungen, die nur schwer durch das eigene Unternehmen gewartet oder angepasst werden können. Dies können entweder Fremdsoftware oder sehr alte Eigenentwicklungen sein, die schlecht dokumentiert oder aufgrund von fehlendem Knowhow nicht mehr wartbar sind.
| |
| | |
| Um auch diese Anwendungen gegen Angriffe absichern zu können, empfiehlt sich der Einsatz einer Web Application Firewall.
| |
| | |
| Dabei handelt es sich um eine '''Application-Level Proxy-Firewall''', die eine zusätzliche Schutzschicht zwischen Webserver und Webanwendung darstellt, welche alle Ein- und Ausgaben der Web-Anwendung zusätzlich auf möglich Angriffe überprüft und diese somit gegen bestimmte Angriffe absichert für die die Anwendung sonst verwundbar wäre.
| |
| | |
| Eine frei verfügbare und weit verbreitete WAF ist '''ModSecurity''' [Tr15]. Es handelt sich dabei um ein Modul für den Webserver Apache, welches wiederum durch Rulesets mit den entsprechenden Filterregeln zur Angriffserkennung ausgestattet werden kann.
| |
| | |
| == Cloud Computing Security ==
| |
| | |
| Der Begriff Cloud-Computing bezeichnet das Auslagern von einzelnen IT-Services hin zu Anbietern dieser Services im Internet. Die Möglichkeiten sind hierbei sehr vielfältig. Sie reichen von der Zurverfügungstellung von Online-Speicherplatz über die gesamte Bandbreite vom einfachen Webservice bis hin zu kompletter virtueller Infrastruktur. Ein Vorteil liegt hierbei in der einfachen Skalierbarkeit der in Anspruch genommenen Services, da sich meist viele Anwender die Ressourcen des Anbieters, je nach gewünschtem Bedarf, teilen. Die Einstiegskosten sind beim Cloud Computing entsprechend geringer als bei der Investition in eigene Ressourcen. Der Hauptvorteil liegt daher in den sich daraus ergebenden wirtschaftlichen Vorteilen durch die variable Mitnutzung komplexer Ressourcen.
| |
| | |
| Innerhalb der Cloudservices wird zwischen vier verschiedenen Servicemodellen unterschieden: Humans as a Service (HuaaS), Software as a Service (SaaS), Platform as a Service (PaaS) und Infrastructure as a Service (IaaS). Die Architektur kann in Form eines Schichtenmodells beschrieben werden, da die einzelnen Servicearten aufeinander aufbauen und die jeweils unten liegende Serviceschicht benötigen. Das Schichtenmodell der Cloud-Architektur ist in Abbildung 21 inklusive der in den jeweiligen Schichten befindlichen Services dargestellt.
| |
| | |
| [[Datei:IT244 21.png|300px|none|thumb|Cloud-Architektur Schichtenmodell ]]
| |
| <span id="_Ref386029914" class="anchor"></span>
| |
| | |
| === Authentifikation bei Cloud-Services ===
| |
| | |
| Für die Authentifikation und die damit verbundene Autorisation werden bei den einzelnen Cloud Storage Anbietern unterschiedliche Verfahren verwendet. Diese können eigene Implementierungen oder allgemein verfügbare Methoden sein.
| |
| | |
| Ein Beispiel dafür ist '''OAuth''' [MP14]. Es ermöglicht die zentrale Verwaltung von Benutzern und Rollen gegenüber Drittanbieter Services. Dabei wird mit Access-Token gearbeitet, die vom Autorisierungs-Server an den Client übergeben werden und ihm damit den Zugriff auf die eigentlichen Ressourcen ermöglichen.
| |
| | |
| Die Verwendung von Access-Token ermöglicht es, Cloud-Dienste mit Applikationen auf unterschiedlichen Geräten zu vernetzen, ohne die eigenen Zugangsdaten preisgeben zu müssen. Diese müssen lediglich bei der Anforderung der Token eingegeben werden. Hat die Anwendung den Token erhalten, kann Sie fortan auf den Cloud-Dienst zugreifen. Jeder Token hat wiederum einen bestimmten Autorisationsumfang innerhalb des Cloud-Dienstes. Wenn der Zugriff der einzelnen Anwendung wieder deaktiviert werden, muss nur der Token deaktiviert werden. Dies hat dann keinen Einfluss auf andere verbundenen Anwendungen.
| |
| | |
| === Cloud Storage Security ===
| |
| | |
| Daten sind innerhalb der verteilten Speicher des Cloud Storage Anbieters meist über Hashwerte adressiert um sie schnell aufzufinden und Redundanzen innerhalb eines Speicherortes zu vermeiden. Das bedeutet jedoch auch, dass ein möglicher Angriff unter Kenntnis des Hashwertes möglich ist. Hier können fehlerhafte Sicherheits-Implementierungen der Anbieter ausgenutzt werden. Einen weiteren möglichen Angriffsvektor stellt in diesem Zusammenhang die Ausnutzung des Geburtstagsparadoxons dar. Hierbei kann dem Speicherdienst der Besitz einer Datei, durch die Generierung einer anderen Datei mit gleichem Hashwert, vorgetäuscht werden (Hash Value Manipulation Angriff). Diese und ähnliche Angriffsszenarien wurden in [Mu11] analysiert und anhand des Cloud Storage Services Dropbox getestet und als durchführbar eingestuft.
| |
| | |
| Neben der besseren Absicherung der Datenübertragungen und der Verifikation des Dateibesitzes [Mu11, S. 9], könnten die Daten mittels Kryptographie auf Dateiebene, vor und nach ihrer Übertragung an den Cloud-Speicher Service abgesichert werden. Dabei können die schwachen Sicherheitsmechanismen der Anbieter, im schlimmsten Fall, lediglich zum Abruf von verschlüsselten Daten ausgenutzt werden.
| |
| | |
| Auch die Verfügbarkeit und Integrität der abgelegten Daten ist ein wesentlicher Aspekt der Cloud Security. So sollten kritische und wichtige Daten auf mehrere Speicherorte gespiegelt abgelegt werden, um eine Verfügbarkeit der mit ihnen verbundenen Services zu gewährleisten [KVB13, S. 48].
| |
| | |
| === Speicherort von Cloud-Daten ===
| |
| | |
| Ein weiterer wichtiger Aspekt der Nutzung von Cloud-Diensten ist der Speicherort. So ist durch die '''EU Datenschutzrichtlinie 95/46/EG''' [Eu00b], welche in Österreich durch das Datenschutzgesetz (DSG) [Bg19] umgesetzt wurde, verboten, personenbezogene Daten aus EU Mitgliedsstaaten an Staaten weiterzugeben, die über keinen gleichwertigen Datenschutz verfügen.
| |
| | |
| Der Nachfolger ist die '''EU Datenschutz-Grundverordnung (DSGVO)''' [Eu17], welche als Verordnung am 25. Mai 2018 in Kraft tritt ist und damit die '''EU Datenschutzrichtlinie 95/46/EG aufhebt'''. Obwohl die DSGVO als Verordnung unmittelbar angewendet wird, hat sie dennoch einige Punkte, welche durch nationales Recht geregelt werden müssen. Diese werden in Österreich durch das neue '''Datenschutz-Anpassungsgesetz 2018 (Datenschutzgesetz 2018 – DSG)''' [Bg17] getroffen, welches ebenfalls am 25. Mai 2018 in Kraft tritt.
| |
| | |
| Einige Staaten haben Gesetze erlassen, welche ihnen, in bestimmten Fällen, Zugriff auf die gespeicherten Daten aller Unternehmen des Landes erlauben. Ein Beispiel für eine solche gesetzliche Befugnis ist der USA Patriot Act. Solche Eingriffe werden natürlich in wenigen Unternehmen gerne gesehen, und verstoßen mitunter gegen Datenschutzbestimmungen in anderen Ländern. [Ar09, S. 15]
| |
| | |
| ==== Unklarheiten und EuGH Urteile zur Datenübermittlung in die USA ====
| |
| | |
| Im Jahr 2000 wurde von der europäischen Kommission daher zusätzlich das '''Safe-Harbor-Abkommen''' verabschiedet, welches gemeinsam mit dem US Handelsministerium [Us14] ausgearbeitet wurde. Es ermöglicht einen Datenaustausch zu US Gesellschaften, sofern diese die Safe-Harbor-Vereinbarung unterzeichnet haben und damit dem Safe-Harbor-Programm beigetreten sind. Dies soll einen ausreichenden Schutz der personenbezogenen Daten gewährleisten, obwohl der grundlegende Datenschutzstandard der USA deutlich unter dem der EU Staaten liegt. [Eu00a]
| |
| | |
| Am 06. Oktober 2015 wurde das Safe-Harbor-Abkommen vom Gerichtshof der Europäischen Union '''wieder für ungültig erklärt''' [Eu15]. ''Die allein auf Grundlage des Safe-Harbor-Abkommens gestützten Übermittlungen sind seit dem Urteilsspruch unmittelbar rechtswidrig. Betroffen sein dürften nicht nur Daten von bekannten Internetunternehmen, sondern auch die Beschäftigtendaten amerikanischer Industriekonzerne. Es ist aber auch zweifelhaft, ob Unternehmen ohne weiteres auf andere in der Richtlinie für Drittstaatentransfers vorgesehene Rechtsgrundlagen ausweichen können.'' [Pe15, S. 805]
| |
| | |
| Daher wurde an einer Nachfolgeregelung gearbeitet und das Abkommen mit dem Namen '''EU-US Privacy Shield''' zwischen der EU und den USA ausgehandelt. Für die Unterfertigung des Abkommens waren Gesetzesänderungen in den USA nötig, welche beispielsweise eine einfachere Klagemöglichkeit von EU Bürgern bei Datenschutzverletzungen vorsehen. Auf Grundlage des Abkommens hat die EU Kommission am 12. Juli 2016 beschlossen [Eu16], dass der Datenschutzstandard der USA nun angemessen ist und dem der EU entspricht.
| |
| | |
| Am 16. Juli 2020 wurde auch das '''EU-US Privacy Shield''' durch den EuGH für '''nicht angemessen und damit nichtig''' erklärt. Die Begründung ist zusammengefasst, dass weiterhin Zugriff auf in die USA übermittelte Personendaten durch US Behörden möglich sind und den Betroffenen keine entsprechenden Rechte zugesichert werden, welche sie gegenüber den US-behörden durchsetzen könnten.
| |
| | |
| ==== Möglichkeiten der internationalen Datenübermittlung ====
| |
| | |
| Eine Möglichkeit für einen rechtmäßigen internationalen Datenverkehr sind Angemessenheitsbeschlüsse. ''Es gibt natürlich auch andere, wie z.B. das Vorliegen „geeigneter Garantien“. Diese können z.B. in verbindlichen internen Datenschutzvorschriften (Binding Corporate Rules), die von der zuständigen Aufsichtsbehörde genehmigt worden sind, bestehen oder in den oben bereits erwähnten Standarddatenschutzklauseln, die von der Europäischen Kommission erlassen oder von einer Aufsichtsbehörde angenommen und von der Kommission genehmigt worden sind. Auch eine ausdrückliche Einwilligung der betroffenen Personen im Einzelfall oder die Erforderlichkeit für die Erfüllung eines Vertrages mit der betroffenen Person kann eine Möglichkeit für den internationalen Datenverkehr sein.'' [WK20]
| |
| | |
| == Angriffsvektoren der Datenübertragung ==
| |
| | |
| In Netzwerken gibt es eine Vielzahl möglicher Angriffsvektoren. Diese betreffen alle Netzwerkschichten und damit sowohl die Transportebene, als auch die Anwendungsebene.
| |
| | |
| Die Arten der Auswirkungen sind dabei sehr vielfältig. Die Übertragungswege können abgehört, manipuliert oder zur Beeinträchtigung der Systemverfügbarkeit missbraucht werden.
| |
| | |
| Nachfolgend sind nun einige dieser Angriffsvektoren, sowie mögliche Gegenmaßnahmen, genauer beschrieben.
| |
| | |
| === Denial-of-Service Angriff ===
| |
| | |
| Bei einem '''DoS (Denial-of-Service)''' Angriff handelt es sich um einen '''Angriff auf die Verfügbarkeit''' eines Server-Dienstes. Dabei wird dieser durch eine '''große zu Menge an Anfragen''' übelastet und ist dadurch nicht mehr verfügbar.
| |
| | |
| DoS Angriffe können unterschiedliche Server-Dienste als Angriffsziel haben. Gängig sind dabei Angriffe gegen die Verfügbarkeit von Webservern, um eine Internetpräsenz zu überlasten und dadurch die Zielseite auszuschalten. Dies kann gerade bei businesskritischen Webseiten, wie beispielsweise Onlineshops, zu erheblichen finanziellen Verlusten führen.
| |
| | |
| Der Angriff beschränkt sich dabei nicht auf valide Server-Anfragen. Es werden meist bewusste Protokollverstöße und fehlende Antworten des Verbindungsaufbaus generiert. Dies kann dann den Server-Dienst in einen Wartezustand bringen und damit eine entsprechende Mehrbelastung verursachen.
| |
| | |
| Heutzutage werden DoS Angriffe über verteilte Netzwerke von mehreren Punkten aus durchgeführt. Sie werden daher als '''DDoS (Distributed Denial of Service)''' bezeichnet. Dies wird meist durch ein Netzwerk aus Viren bewerkstelligt, welches vom Angreifenden zentral gesteuert werden kann. Diese Art des Netzwerkes wird als '''Bot-Netz''' bezeichnet, da die Viren ihre Tätigkeiten ferngesteuert durchführen. Durch die Verteilung des Angriffs auf mehreren Ausgangspunkten ist es für die Firewall des angegriffenen Servers schwieriger zu unterscheiden, welche Anfragen nun gutartig oder bösartig sind.
| |
| | |
| Da es leicht möglich ist bestehende Bot-Netze zu mieten, ist dies ein sehr gefährlicher und aktueller Angriffsvektor. Der Angreifende muss dazu oft nicht einmal mehr das nötige Know-How besitzen, sondern lediglich über die entsprechenden Angebotsquellen verfügen. Die Bedienung erfolgt dann über ein simples User-Interface, mit dem das Netz im Mietzeitraum gesteuert werden kann.
| |
| | |
| Um DDoS Angriffen vorzubeugen, sollten entsprechende Firewall-Regeln eingerichtet sein, welche '''ungültige Pakete und Verbindungen blockieren''' (siehe Stateful-Firewalls in 5.2). Wichtig ist dabei, den Angriff so nahe wie möglich bei den Angreifenden zu filtern. Dies kann durch providerseitige Filtermaßnahmen erreicht werden. Auch existieren, je nach betroffenem Server-Dienst, meist protokollspezifische Maßnahmen die '''Auswirkungen abzuschwächen'''.
| |
| | |
| Weiter sollten Maßnahmen zur '''Lastverteilung''' von akut auftretenden Anfragespitzen geplant werden. Dies kann in einem großen Rechenzentrum beispielsweise durch die dynamische Verteilung von Serverressourcen geschehen.
| |
| | |
| === Sniffing ===
| |
| | |
| Beim Sniffing (Schnüffeln) handelt es sich um das '''Abhören von Datenverbindungen'''. Dabei werden Datenpakete mitgehört, welche in öffentlich zugänglichen Netzen übertragen werden. Handelt es sich dabei um unverschlüsselte Daten können diese ausgelesen und interpretiert werden.
| |
| | |
| Sniffing kann durch '''Verschlüsselung''' des Datenverkehrs entgegengewirkt werden. Der Tausch des zugehörigen Schlüssels kann dabei mittels '''Schlüsseltauschverfahren''' (siehe Lektion 3.5) sichergestellt werden. Dies verhindert nicht das Abhören der Pakete selbst. Die darin enthaltene Information wird für den Abhörenden jedoch unbrauchbar.
| |
| | |
| === Man-in-the-Middle Angriff ===
| |
| | |
| Bei einem Man-in-the-Middle Angriff werden die Datenpakete nicht – wie beim Sniffing – nur abgehört, '''sondern über den Rechner des Angreifenden umgeleitet'''. Dadurch ist es möglich, den Inhalt der Daten zu manipulieren.
| |
| | |
| Einem Opfer eines Man-in-the-Middle Angriffs kann daher ein geänderter Inhalt übermittelt werden. Es geht allerdings davon aus, den angefragten und gewünschten Inhalt bekommen zu haben und merkt dies meist auch nicht. Damit ist es dem Angreifenden beispielsweise möglich, durch manipulierte Zugangsseiten und Formulare Daten zu erfragen oder, im Rahmen eines Downloads, einen Schadcode auszuliefern. Diese Umleitung auf bösartige Formularseiten wird auch als '''Pharming''' bezeichnet.
| |
| | |
| Beim Diffie-Hellmann Schüsseltausch ist es beispielsweise durch einen Man-in-the-Middle Angriff möglich, die Datenverbindung abzuhören. Der Angreifende gibt sich dabei an beiden Seiten als die gewünschte Gegenseite aus. Diese tauschen damit unbewusst beide einen Schlüssel mit dem Angreifenden aus und nicht mit der gewünschten Gegenstelle. Der Man-in-the-Middle muss den Datenverkehr in beide Richtungen nur immer jeweils mit dem zugehörigen Schlüssel der Gegenstelle verschlüsseln und entschlüsseln und kann dazwischen alle Daten im Klartext lesen.
| |
| | |
| Als Gegenmaßnahme zu Man-in-the-Middle Angriffen können Verfahren eingesetzt werden, welche die Daten zusätzlich mittels Zertifikaten '''signieren''' (siehe Lektion ). Da sich der Private-Key nur im Besitz des jeweiligen Absenders befindet, können die Daten nicht unbemerkt durch den Angreifenden manipuliert werden.
| |
| | |
| === Google Hacking ===
| |
| | |
| Viele Angriffe auf Webserver geschehen nicht gezielt auf bestimmte Systeme. Stattdessen suchen die Angreifer nach beliebigen verwundbaren Systemen, indem sie die Indizierung der Seiten in Suchmaschinen ausnutzen.
| |
| | |
| Dieser Angriffsvektor wird als Google Hacking bezeichnet. Dabei handelt es sich noch nicht um einen direkten Angriff, sondern eine Methode des Informationsgewinnes über mögliche verwundbare Systeme.
| |
| | |
| Beim Google Hacking wird in Google nach bestimmten HTML-Headern und Dateinamen gesucht. Das können beispielsweise bestimmte Versionen oder Dateien eines Content-Management-Systems (CMS) oder Debug-Informationen von Webservern sein.
| |
| | |
| Auch kann z.B. gezielt nach Passwortdateien gesucht werden, welche irrtümlich frei abrufbar sind.
| |
| | |
| Als Gegenmaßnahme sollten Fehlermeldungen immer durch '''eigene Fehlerseiten''', und nie direkt durch die eigene Ausgabe des Scripts angezeigt werden. Interne Fehlercodes und Fehlerdetails dürfen nur in '''Logdateien''' gespeichert und niemals dem Endanwender gezeigt werden. Auch sollte unbedingt darauf geachtet werden, den '''Zugriff''' auf Webverzeichnisse mit Administrationsseiten und internen Dateien zu '''beschränken'''. Die '''Standardpfade''' für Administrationsbereiche von CMS Umgebungen sollten ebenfalls immer '''geändert''' werden.
| |
| | |
| === Injection ===
| |
| | |
| Bei Injection handelt es sich um einen Angriff durch das Einbringen von Schadcode und Kommandos zur Ausführung direkt am angegriffenen Webserver. Dabei werden unsauber programmierte Webformulare und Übergabeparameter ausgenutzt, um den Code vom jeweiligen Interpreter am Server ausführen zu lassen.
| |
| | |
| Injection Angriffe sind die am weitest verbreiteten, da gerade im Web viele unsaubere Programmiercodes in Tutorials und Foren kursieren, welche wiederum von oft Entwicklern wiederverwendet werden. Einen Hinweis auf die Behebung der Schwachstellen findet man dabei sehr selten. Die Injection Angriffe befinden sich bereits seit 2007 auf Platz 1 der OWASP Top 10 [Ow15a].
| |
| | |
| Da bei Injection Angriffen Schadcode am Server ausgeführt werden kann, handelt es sich um eine sehr schwerwiegende Sicherheitslücke, welche zu Datenverlust und Datenverfälschung, sowie Kontrollverlust über den gesamten Webserver führen kann.
| |
| | |
| Die bekannteste Variante der Injection-Angriffe ist die SQL-Injection. Dabei werden unsauber programmierte SQL-Aufrufe ausgenutzt, welche die Eingabewerte direkt an in den SQL-Befehl integrieren. Die Eingabewerte können von Angreifenden dann dazu verwendet werden, andere SQL-Befehle auszuführen, oder den jeweiligen Befehl um weitere Bestandteile zu erweitern.
| |
| | |
| Ein Bespiel für eine verwundbare SQL Abfrage lautet:
| |
| | |
| <blockquote>''String query = "SELECT * FROM accounts WHERE custID='" + request.getParameter("id") +"'";''</blockquote>
| |
| Dabei kann durch Übergabe des Wertes:
| |
| | |
| ''?id=' or '1'='1''
| |
| | |
| eine Abfrage erzeugt werden, die alle möglichen Einträge der Tabelle wiedergibt, da die Bedingung damit nun immer wahr ist.
| |
| | |
| Die eigentliche, an den Datenbank-Server übermittelte SQL-Abfrage lautet in diesem Fall:
| |
| | |
| ''SELECT * FROM accounts WHERE custID='<u>' or '1'='1'</u>;''
| |
| | |
| Auch kann durch fehlerhafte Werte ein Fehler bewusst herbeigeführt werden, der auf einem schlecht konfigurierten System für den Benutzer ersichtlich zurückgegeben wird. Durch die Fehlermeldung kann dann oft auf die Konfiguration und Versionierung der Serversoftware rückgeschlossen werden, was weitere Angriffsversuche wiederum erleichtert.
| |
| | |
| Um Injection Angriffe zu verhindern ist es wichtig, jeden '''Dateninput''', ganz gleich, ob es ein Benutzerformular oder eine Programmschnittstelle ist, zu '''validieren''' oder entsprechend umzucodieren. Dies kann mittels eigener Implementierung von Funktionen für die Anpassung und Überprüfung der Überbewerte, oder dem Einsatz einer entsprechenden API erfolgen. Ist keine API verfügbar, sollten alle möglichen Metazeichen sehr sorgfältig durch eine eigene Funktion, vor der weiteren Verarbeitung entschärft werden. Auch besteht die Möglichkeit mittels Whitelist nur explizit erlaubte Schriftzeichen zuzulassen und alle anderen Zeichen zu filtern. Dies ist jedoch meist schwierig, da manche Metazeichen von den Anwendungen benötigt werden.
| |
| | |
| === Broken Authentication and Session Management ===
| |
| | |
| Dabei handelt es sich um den Diebstahl von Zugangsdaten oder dem validen Zustand eines authentifizierten Anwenders.
| |
| | |
| Die meisten Internetzugriffe, wie beispielsweise über HTTP, erfolgen transaktionslos. Das bedeutet, dass jede Anfrage an einen Webserver unabhängig von den vorangegangenen Anfragen durchgeführt und beantwortet wird. Um dem Client eine durchgängige Anwendungsbenutzung mit den entsprechenden, serverseitig gespeicherten Zuständen, zu ermöglichen, bedient man sich hier sogenannter Sessions. In einer Session werden bestimmte Zustände bzw. Variablen serverseitig zwischengespeichert und bei der nächsten Anfrage des Clients wiederverwendet. Erst dadurch sind Anwendungen möglich, bei denen sich der Anwender nur zu Beginn anmelden muss und dann alle übrigen Zugriffe mit den für ihn hinterlegten Berechtigungen durchführen kann, ohne seine Authentifizierung bei jedem Zugriff wiederholen zu müssen.
| |
| | |
| Um dem Server mitzuteilen, welche Session für den aktuellen Zugriff verwendet werden soll, übergibt der Client eine entsprechende Session-ID, die ihm beim ersten Zugriff vom Server mitgeteilt wurde.
| |
| | |
| Der Angreifende versucht nun die Session-ID zu stehlen, damit er diese bei seinem eigenen Client hinterlegen und somit Serveranfragen mit der Identität des Opfers durchzuführen. Um die Session-ID zu erhalten gibt es mehrere Möglichkeiten. Die häufigsten sind, das Wiederverwenden von alten Session-ID’s durch den Server durch falsche Session-Timeouts, die Übergabe der Session-ID über den Webpfad (die URL) und die damit verbundene irrtümliche Weitergabe der ID durch den Anwender, sowie das Abhören einer der Session-ID einer unverschlüsselten Verbindung.
| |
| | |
| Um diese Art von Angriffen zu verhindern, sollte ein '''professionelles Login- und Session-Management''' implementiert werden. Von Eigenentwicklungen ist hierbei abzuraten, da dadurch oft Fehler entstehen können, die wiederum ein Ausnutzen durch potenzielle Angreifer vereinfachen. Auch sollte besonderer Wert auf die Verhinderung von Cross Site Scripting Attacken (siehe 5.6.7) und der Verschlüsselung der Datenverbindungen (z.B.: durch Verwendung von HTTPS) gelegt werden.
| |
| | |
| Zur Einhaltung der Anforderungen an Authentifizierung und Session-Management wurde der der '''OWASP Application Security Verification Standard''' [Ow15b] entwickelt, dessen Einhaltung ebenfalls empfohlen werden kann.
| |
| | |
| === Cross-Site Scripting (XSS) ===
| |
| | |
| Beim Cross Site Scripting wird die Ausgabe eines, vorher an die Website übergebenen, Wertes ausgenutzt. Wird der Wert direkt in den Webseitencode eingefügt, kann dadurch Schadcode eingeschleust werden, der im Clientbrowser ausgeführt wird.
| |
| | |
| Ein Beispiel hierfür sind Internet-Foren und Login-Formulare ohne Absicherung. Bei einem Forenbeitrag mit entsprechend eingefügtem Schadcode kann eine Ausführung bei jedem einzelnen User erfolgen, der sich den Forenbeitrag ansieht. Im Beispiel des Login Formulars könnte eine Login-Eingabe der Benutzerdaten abgefangen und an einen Server des Angreifers übermittelt werden. Leitet der Schadcode die Anfrage danach wieder korrekt an die Login-Funktion der Webseite weiter, bemerkt der Anwender den Angriff nicht, der Angreifer hat hingegen erfolgreich seine Logindaten erhalten.
| |
| | |
| Eine weitere Angriffsmöglichkeit ist die Übernahme der Session-ID des Anwenders, indem ein Schadcode eingeschleust wird, der die aktuelle Session-ID an den Webserver des Angreifers übermittelt.
| |
| | |
| Um Cross Site Scripting zu verhindern, müssen die '''übergebenen Werte''' der Website, ähnlich der Vorbeugung von Injektion Angriffen, '''überprüft''' werden. Zusätzlich müssen alle '''nicht vertrauenswürdigen Zeichen''' der Ausgabewerte vor dem Einfügen in den HTML Code durch ihre entsprechenden '''Metazeichen ersetzt''' werden. Für diesen Zweck gibt es in den meisten Skriptsprachen entsprechende Funktionen, welche valide und ungefährliche Ausgabedaten generieren.
| |
| | |
| Die Mozilla Foundation hat eine '''Content Security Policy''' [Mo15] veröffentlicht, mit deren Einhaltung möglichen Cross Site Scripting Attacken sicher vorgebeugt werden kann.
| |
| | |
| == Wiederholungsaufgaben/Übungen ==
| |
| | |
| '''5.7.1 Nennen Sie fünf Sicherheitsprotokolle der transportorientierten Netzwerk-Schichten und der fünf Sicherheitsprotokolle der Anwendungsorientierten Netzwerk-Schichten.'''
| |
| | |
| '''5.7.2 Was sind Firewalls? Welche Kategorien von Firewalls gibt es?'''
| |
| | |
| '''5.7.3 Was ist der Unterschied zwischen einer Packet-Filter Firewall und einer Stateful Firewall?'''
| |
| | |
| '''5.7.4 Was sind Application-Level Firewalls?'''
| |
| | |
| '''5.7.5 Was bedeutet VPN und was ist seine Aufgabe?'''
| |
| | |
| '''Nennen Sie fünf VPN Protokolle.'''
| |
| | |
| '''5.7.5 Was sind die OWASP Top 10?'''
| |
| | |
| '''Nennen Sie die ersten drei Plätze.'''
| |
| | |
| '''5.7.6 Worauf ist bei der Speicherung von Daten in der Cloud besonders zu achten?'''
| |
| | |
| '''5.7.7 Was bedeutet DoS und was ist ein DoS Angriff?'''
| |
| | |
| '''5.7.8 Was ist der Unterschied zwischen Sniffing und einem Man-in-the-Middle Angriff?'''
| |
| | |
| '''5.7.9 Was ist ein Injection-Angriff?'''
| |
| | |
| '''5.7.10 Was ist Broken Authentication and Session Management?'''
| |
| | |
| '''5.7.11 Was ist Cross-Site-Scripting?'''
| |
| | |
| = Anhang A: Lösungen zu den Aufgaben =
| |
| | |
| '''1.7.1 Erklären Sie worin sich die Begriffe Informationssicherheit, IT-Sicherheit und Datenschutz unterscheiden.'''
| |
| | |
| Vgl. Lektion 1.2
| |
| | |
| '''1.7.2 Was ist die CIA-Triade? Erklären Sie kurz was genau unter C, I und A verstanden wird.'''
| |
| | |
| Vgl. Lektion 1.3 - 1.3.3
| |
| | |
| '''1.7.3 Welche Kontrollmechanismen gibt es, um die Ziele der CIA-Triade analysieren zu können?'''
| |
| | |
| Vgl. Lektion 1.3.4
| |
| | |
| '''1.7.4 Was versteht man unter Schwachstellen, Bedrohungen und Maßnahmen und wie hängen sie zusammen?'''
| |
| | |
| Vgl. Lektion 1.3.5
| |
| | |
| '''1.7.5 Zählen Sie wesentliche Standards der Informationssicherheit auf und erläutern Sie kurz ihre Herkunft und ihren Zweck.'''
| |
| | |
| Vgl. Lektion 1.4
| |
| | |
| '''1.7.6 Sie sind mit der Durchführung eines Projektes zur Einführung von Informationssicherheit im Unternehmen beauftragt. Welches System werden Sie dazu einführen und was muss nach Projektende unbedingt beachten werden und warum?'''
| |
| | |
| Vgl. Lektion 1.5
| |
| | |
| '''1.7.7 Erklären Sie kurz den Begriff des IT-Business Continuity Managements. Welche Analysemaßnahmen müssen darin durchgeführt werden und wie hängen sie zusammen?'''
| |
| | |
| Vgl. Lektion 1.6
| |
| | |
| '''1.7.8 Wie funktioniert eine Risikoanalyse nach dem Grundschutzansatz?'''
| |
| | |
| Vgl. Lektion 1.6.3.2
| |
| | |
| '''2.4.1 Erklären Sie den Zusammenhang der Begriffe "Können, Wollen und Wissen" der Security Awareness.'''
| |
| | |
| Vgl. Lektion 2.1
| |
| | |
| '''2.4.2 Welche Punkte solle ein Sensibilisierungsprogramm für die Informationssicherheit beinhalten?'''
| |
| | |
| Vgl. Lektion 2.1.2
| |
| | |
| '''2.4.3 Erklären Sie die Begriffe "Black Hat", "White Hat" und "Gray Hat".'''
| |
| | |
| Vgl. Lektion 2.2.1
| |
| | |
| '''2.4.4 Nach welchen ethischen Grundsätzen sollten IT-Sicherheitsspezialisten handeln?'''
| |
| | |
| Vgl. Lektion 2.2.2
| |
| | |
| '''2.4.5 Worum handelt es sich bei Social Engineering? Welche Faktoren begünstigen seinen Erfolg? Erklären Sie diese kurz.'''
| |
| | |
| Vgl. Lektion 2.3
| |
| | |
| '''3.8.1 Erklären Sie den Cäsar-Algorithmus anhand der Verschlüsselung des Wortes "WIBA" durch Cäsar 5.'''
| |
| | |
| Vgl. Lektion Lektion 3.
| |
| | |
| Geheimtext: BNGF
| |
| | |
| '''3.8.2 Erklären Sie die Begriffe Klartext, Geheimtext, und Chiffre. Stellen Sie Ihre Zusammenhänge bei der Verschlüsselung und Entschlüsselung grafisch dar.'''
| |
| | |
| Vgl. Lektion 3.1
| |
| | |
| '''3.8.3 Erklären Sie den Begriff “Security by Obscurity“? Welches Prinzip spricht dagegen?'''
| |
| | |
| Vgl. Lektion 3.2
| |
| | |
| '''3.8.4 Wodurch unterscheiden sich symmetrische und asymmetrische Kryptographie-Verfahren?'''
| |
| | |
| Vgl. Lektion 3.3, 3.4
| |
| | |
| '''3.8.5 Wie läuft der Diffie-Hellmann Schlüsseltausch ab. Erklären Sie ihn anhand eines einfachen Beispiels mit Farbkübeln ODER mathematisch.'''
| |
| | |
| Vgl. Lektion 3.5
| |
| | |
| '''3.8.5 Was ist Hashing und wozu wird es eingesetzt?'''
| |
| | |
| Vgl. Lektion 3.6
| |
| | |
| '''3.8.6 Was ist ein Brute-Force Angriff?'''
| |
| | |
| Vgl. Lektion 3.7.1
| |
| | |
| '''4.4.1 Was ist der Unterschied zwischen Identifikation, Authentifikation und Autorisation?'''
| |
| | |
| Vgl. Lektion 4.1.1 - 4.1.4
| |
| | |
| '''4.4.2 Was ist eine Zwei-Faktor-Authentifikation?'''
| |
| | |
| Vgl. Lektion 4.1.3
| |
| | |
| '''4.4.3 Welche drei Zugriffssteuerungsmodelle gibt es?'''
| |
| | |
| Vgl. Lektion 4.1.6
| |
| | |
| '''4.4.4 Erklären Sie das Modell der Eigner-definierten Zugriffssteuerung.'''
| |
| | |
| Vgl. Lektion 4.1.6
| |
| | |
| '''4.4.5 Was sind Zertifikate und die damit verbundenen Vertrauensmodelle?'''
| |
| | |
| Vgl. Lektion 4.3
| |
| | |
| '''4.4.6 Was bedeutet PKI und wer sind ihre Hauptakteure? Wie hängen diese Akteure zusammen?'''
| |
| | |
| Vgl. Lektion 4.3.1
| |
| | |
| '''4.4.7 Eine Passwortrichtlinie fordert ein Passwort, bestehend aus Kleinbuchstaben, Großbuchstaben und Ziffern mit einer Länge von 10 Zeichen. Wie wird die Komplexität des Passworts berechnet (wie viele mögliche Passwörter gibt es)?'''
| |
| | |
| Vgl. Lektion 4.2
| |
| | |
| '''5.7.1 Nennen Sie fünf Sicherheitsprotokolle der transportorientierten Netzwerk-Schichten und der fünf Sicherheitsprotokolle der Anwendungsorientierten Netzwerk-Schichten.'''
| |
| | |
| Vgl. Lektion 5.1.1 und 5.1.2
| |
| | |
| '''5.7.2 Was sind Firewalls? Welche Kategorien von Firewalls gibt es?'''
| |
| | |
| Vgl. Lektion 5.2
| |
| | |
| '''5.7.3 Was ist der Unterschied zwischen einer Packet-Filter Firewall und einer Stateful Firewall?'''
| |
| | |
| Vgl. Lektion 5.2
| |
| | |
| '''5.7.4 Was sind Application-Level Firewalls?'''
| |
| | |
| Vgl. Lektion 5.2
| |
| | |
| '''5.7.5 Was bedeutet VPN und was ist seine Aufgabe?'''
| |
| | |
| '''Nennen Sie fünf VPN Protokolle.'''
| |
| | |
| Vgl. Lektion 5.3
| |
| | |
| '''5.7.5 Was sind die OWASP Top 10?'''
| |
| | |
| '''Nennen Sie die ersten drei Plätze 3.'''
| |
| | |
| Vgl. Lektion 5.4.2
| |
| | |
| '''5.7.6 Worauf ist bei der Speicherung von Daten in der Cloud besonders zu achten?'''
| |
| | |
| Vgl. Lektion 5.5.2 und 5.5.3
| |
| | |
| '''5.7.7 Was bedeutet DoS und was ist ein DoS Angriff?'''
| |
| | |
| Vgl. Lektion 5.6.1
| |
| | |
| '''5.7.8 Was ist der Unterschied zwischen Sniffing und einem Man-in-the-Middle Angriff?'''
| |
| | |
| Vgl. Lektion 5.6.2 und 5.6.3
| |
| | |
| '''5.7.9 Was ist ein Injection-Angriff?'''
| |
| | |
| Vgl. Lektion 5.6.5
| |
| | |
| '''5.7.10 Was ist Broken Authentication and Session Management?'''
| |
| | |
| Vgl. Lektion 5.6.6
| |
| | |
| '''5.7.11 Was ist Cross-Site-Scripting?'''
| |
| | |
| Vgl. Lektion 5.6.7
| |
Zugriffssteuerung
Die Zugriffssteuerung (Access Control) regelt den Zugriff und die Kommunikation von IT-Systemen mit ihren Anwendern, Ressourcen und anderen IT-Systemen. Es handelt sich dabei um eine zentrales Element der meisten IT-Systeme, da davon alle Schutzziele (Vertraulichkeit, Integrität und Verfügbarkeit; siehe Lektion 1.3) betroffen sein können.
In dieser Lektion werden die grundlegenden Begriffe der Zugriffssteuerung erläutert und weiter die konkreten Techniken der Zertifikate und der Fernzugriffe sowie potentielle Angriffsvektoren näher behandelt.
Grundbegriffe der Zugriffssteuerung
Um die Schutzziele der Vertraulichkeit, Integrität und Verfügbarkeit des Datenaustausches mit IT-Systemen gewährleisten zu können müssen die jeweiligen Anforderungen an die Kommunikation definiert werden. Dabei gibt es einige wesentliche Begriffe, welche oft auch von Technikern falsch verwendet werden. Beispielsweise werden Identifikation, Authentifikation und Autorisation manchmal fälschlicherweise als Akronyme verwendet, obwohl es sich dabei um grundlegend unterschiedliche Begriffe handelt. Auch ist es wichtig zu wissen, wie bestimmte Anforderungen an die Zugriffssteuerung implementiert werden können.
Zugriff
Beim Zugriff handelt es sich um die Kommunikation mit einem IT-System. Diese kann sowohl mit einem Anwender, als auch mit einem anderen IT-System oder seiner Ressourcen stattfinden. In den meisten Fällen gibt es dabei Anforderungen an Identifikation, Authentifikation und Autorisation, sowie an die Nachverfolgbarkeit und Nichtabstreitbarkeit (siehe weiter auch 4.1.2, 4.1.3, 4.1.4 und 4.1.5).
Ressourcen können dabei alle Komponenten sein, welche einen Zugriff auf Daten ermöglichen oder diese beinhalten, wie beispielsweise: Datenbanken, Tabellen und Dateien. Die Zugriffe können dabei sowohl über lokale Verbindungen, als auch über das Netzwerk/Internet oder unterschiedliche Datenträger erfolgen.
Identifikation
Die Identifikation bezeichnet die Benennung eines bestimmten Systems oder einer Person, welche auf ein System zugreifen möchte. Dabei ist weder sichergestellt durch wen diese Benennung erfolgt ist, noch ob es sich bei der Benennung tatsächlich um das benannte System oder die benannte Person handelt.
Zur Identifikation dienen oft die eindeutige User-ID, die E-Mailadresse oder der Name.
Ein Beispiel ist eine Anwesenheitsliste: Die Protokollführung schreibt die Namen der anwesenden Personen auf, welche diese wiederum identifizieren. Dabei ist jedoch noch nicht sichergestellt, ob die jeweiligen Personen tatsächlich die sind, die sie vorgeben zu sein. Im schlechtesten Fall sind sie der Protokollführung nicht bekannt und identifizieren sich durch Nennung ihres Namens.
Authentifikation
Die eindeutige Identifikation einer Person oder eines Systems wird als Authentifikation bezeichnet. Erst dadurch wird sichergestellt, dass es sich dabei tatsächlich um die Identifizierten handelt.
Es gibt drei unterschiedliche Kategorien von Authentifikationsmethoden und -merkmale:
- Wissen (was jemand weiß),
- Besitz (was jemand besitzt) und
- Biometrie (was jemand ist).
Die drei Merkmale Wissen, Besitz und Biometrie werden oft auch als „Wissen, Haben und Sein“ bezeichnet.
Eine häufig eingesetzte Methode ist das Passwort. Dieses ist in der Kategorie des Wissens eingeordnet, da es von jedem eingesetzt werden kann, der es kennt. Es kann daher auch weitergegeben oder ausgespäht werden. Je komplexer es ist, desto leichter kann es auch vergessen werden. Je häufiger es verwendet wird, desto schneller kann es herausgefunden werden. Zu komplexe Passwörter sind daher keine gute Lösung zur sicheren Authentifikation, da sie von vielen Usern vergessen oder aufgeschrieben werden. Dasselbe gilt für zu einfache Passwörter, da sie leicht erraten werden können.
Beim Merkmal des Besitzes wird die Authentifikation über etwas erreicht, dass nur der zu Authentifizierende besitzt. Beispiele dafür sind ein Personalausweis oder eine Chipkarte (z.B. eine Bankomatkarte). Damit die Weitergabe dieses Merkmals überhaupt nicht, oder nur sehr schwierig möglich ist, sollte es möglichst nicht vervielfältigt werden können.
Unter Biometrie werden Merkmale verstanden, die an eine bestimmte Person (oder ein bestimmtes System) gebunden sind. Sie sind öffentlich sichtbar oder beobachtbar, jedoch nicht leicht duplizierbar. Häufig bekannte Beispiele für biometrische Merkmale sind Fingerabdrücke, Venenmuster, die Iris-Muster der Augen und Stimmmuster. Weitere, oft weniger bekannte, Merkmale sind jedoch auch die Art des Ganges einer Person, ihre Tastenanschläge, ihr Schreibstil und aber auch die Art und Weise wie sie sich innerhalb eines Programmes oder einer Webseite bewegen.
Je nach Sicherheitsanforderungen können dabei auch mehrere Merkmale kombiniert werden um die Authentifizierungsqualität noch weiter zu verstärken. Ein bekanntes Beispiel dafür ist die zur Bargeldbehebung mittels Bankomatkarte notwendige Authentifizierung. Dabei wird ein Besitzmerkmal (Bankomatkarte) mit einem Wissensmerkmal (PIN-Code) kombiniert. Ist jemand im Besitz der Karte, benötigt er zusätzlich noch den PIN-Code und umgekehrt. Mit einem der beiden Merkmale allein kann keine gültige Authentifikation erfolgen und damit auch kein Geld behoben werden.
Werden zwei Merkmale kombiniert, wird dies auch als Zwei-Faktor-Authentifizierung bezeichnet. Wichtig ist dabei immer, dass zwei Merkmale unterschiedlicher Kategorien (Wissen, Besitz und Biometrie) kombiniert werden. Die Kombination zweier Merkmale derselben Kategorie, erhöht zwar die Sicherheit, gilt dabei jedoch nicht als Zwei-Faktor-Authentifizierung. Die einzelnen Merkmalskategorien und die sich daraus ergebenen Authentifizierungslevel sind weiter in Abbildung 15 dargestellt.
Ob die Authentifizierungsqualität durch den Einsatz von drei Faktoren weiter stark erhöht werden kann, ist umstritten. Dies ist stark von den jeweils eingesetzten Techniken, aber auch von deren Akzeptanz bei den Anwendern, abhängig.
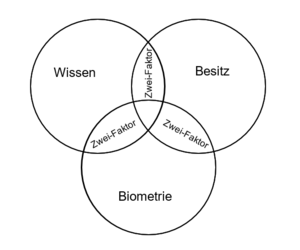
Authentifizierungsfaktoren: Wissen, Besitz und Biometrie
Autorisation
Bei der Autorisation handelt es sich um die Berechtigung, die eine authentifizierte Person oder ein authentifiziertes System für einen bestimmten Zugriff hat. So können in einem System beispielsweise unterschiedliche Rollen existieren, welche wiederum unterschiedliche Zugriffe ermöglichen. Wie ein System unterschiedliche Autorisationen verwaltet und behandelt wird als Zugriffssteuerungsmodell bezeichnet. Die unterschiedlichen Arten von Zugriffssteuerungsmodellen sind nachfolgend in 4.1.6 genauer beschrieben.
Die Authentifikation stellt damit sicher, dass es sich um jemand bestimmten handelt und die Autorisation regelt wiederum welche bestimmten Rollen welche Zugriffe bekommen.
Nachverfolgbarkeit und Nichtabstreitbarkeit
Bei der Nachverfolgbarkeit und Nichtabstreitbarkeit handelt es sich um Zugriffsmerkmale, welche eine genaue Dokumentation der jeweiligen Systemkommunikation ermöglichen. Je nach Anforderung wird dabei dokumentiert, welche Zugriffe stattgefunden haben und unter welchen (Sicherheits-)Parametern diese aufgebaut wurden. Um eine lückenlose Nachverfolgbarkeit sicherzustellen, ist es erforderlich, den Erfolg der Authentifikation und die erteilte Autorisation zu dokumentieren.
In manchen Fällen ist es weiter erforderlich eine Nichtabstreitbarkeit von Zugriffen zu ermöglichen. Als Nichtabstreitbarkeit wird bezeichnet, das eine Person die Erstellung einer gesendeten Nachricht nicht mehr abstreiten kann. Dies beinhaltet auch automatisch die Integrität der Nachricht. Es muss daher für eine Nichtabstreitbarkeit auch sichergestellt sein, dass die Nachricht nicht mehr verändert wurde, da anderenfalls der Absender behaupten könnte, ursprünglich eine andere Nachricht erstellt zu haben.
Die Nichtabstreitbarkeit kann mit Hilfe asymmetrischer Kryptographie Methoden sichergestellt werden (siehe Lektion 3.4). Dabei wird der Hashwert einer Nachricht mit dem privaten Schlüssel des Absenders verschlüsselt. Zur Prüfung der Integrität (ob die Nachricht der abgesendeten Nachricht entspricht), muss nun nur noch der verschlüsselte Hashwert mit dem öffentlichen Schlüssel entschlüsselt und mit dem aktuellen Hashwert der Nachricht verglichen werden. Da die Verschlüsselung nur vom Besitzer des privaten Schlüssels durchgeführt werden kann, ist hier eine Nichtabstreitbarkeit gewährleistet.
Zugriffssteuerungsmodelle
Zugriffssteuerungsmodelle (Access Control Models) regeln die Art und Weise von Zugriffen. Sie definieren dabei die möglichen Regeln und Ziele der Zugriffe und stellen diese den jeweiligen Zugriffssteuerungstechnologien zur Verfügung. Die Modelle sind ein wesentlicher Bestandteil des jeweiligen Betriebssystems, da sie grundlegende Entscheidungen der internen Zugriffe beeinflussen. Sie sind daher direkt im Kern des Betriebssystems integriert. [Ha13, 219]
Es wird zwischen drei verschiedenen Kategorien von Zugriffssteuerungsmodellen unterschieden:
- Eigner-definierte Zugriffssteuerung (DAC: Discretionary Access Control),
- Obligatorische Zugriffssteuerung (MAC: Mandatory Access Control) und
- Rollenbasierte Zugriffssteuerung (RBAC: Role Based Access Control).
Da eine gleichzeitige Unterstützung mehrerer Modelle meist nicht sinnvoll realisierbar ist, ist die Modellauswahl eine grundlegende Entscheidung für das IT-System. Das am häufigsten anzutreffende Modell ist das der Eigner-definierten Zugriffssteuerung.
Eigner-definierte Zugriffssteuerung
Bei der Eigner-definierten Zugriffssteuerung haben alle Daten einen definierten Eigner (oft auch als Besitzer bezeichnet). Dieser ist fest mit den Daten oder der Datei verbunden. Der Eigner definiert, welche Personen oder Systeme Zugriff auf die Daten erhalten und in welcher Form (z.B.: lesen, schreiben, ändern, ausführen oder verweigern).
Die Zugriffsberechtigungen sind dabei meist über Access Control Lists (ACL‘s) definiert. Dabei handelt es sich um eine Auflistung aller Berechtigten und der jeweils zugeordneten Rechte.
Dieses Modell ist in aktuellen Windows-, Linux- und Mac-Systemen anzutreffen. In diesen Systemen hat jede Datei einen Besitzer und eine entsprechende ACL zugeordnet.
Einzelne User und Systeme können hier meist in Berechtigungsgruppen zusammengefasst werden. In diesem Fall können die ACL’s sowohl Zuordnungen einzelner User und Systeme, als auch Berechtigungsgruppen enthalten.
Obligatorische Zugriffssteuerung
Die obligatorische Zugriffssteuerung findet ihre Anwendung in Bereichen mit sehr hohem Sicherheitsbedarf. Sie kommt daher meist in behördlichen und militärischen Systemen zum Einsatz.
In diesem Modell ist keine individuelle Behandlung einzelner User und Dateien vorgesehen. Der Zugriff ist abhängig von unterschiedlichen Sicherheitsstufen, auf denen sich Daten und User befinden. Meist ist dabei eine Änderung von Dateiberechtigungen durch die User nicht möglich.
Die Umsetzung der Sicherheitsstufen erfolgt durch Vertrauens-Levels (Clearance) für User und Sensitivitäts-Labels für Dateien. Mögliche Sicherheitsstufen wären z.B.: nicht vertraulich, vertraulich, geheim und streng geheim.
Der Zugriff auf Daten erfolgt gemäß den jeweiligen Sicherheitsstufen. Sind die Stufe der Datei und die Stufe des Users ident, darf er auf die Daten zugreifen. Ob er auf Daten von darunterliegenden Stufen zugreifen darf, kann unterschiedlich implementiert sein. Meist dürfen Informationen nur von niedrigeren Levels zu höheren Levels übertragen werden und nicht umgekehrt. Zugriffe zwischen unterschiedlichen Levels werden dabei meist auch von eigenen Überwachungsdienstprogrammen gesteuert und genehmigt.
Zusätzlich werden meist hierarchische Zuordnungen vergeben, in denen sich sowohl Daten, als auch User befinden können. Die hierarchische Zuordnung steht dann nochmals über der Zuordnung des Sicherheitslevels. Damit ist sichergestellt, dass die Zugriffe nicht nur gemäß des Vertrauens-Levels, sondern auch gemäß der Zugriffs-Notwendigkeit erfolgen. Befindet sich ein User nicht in derselben hierarchischen Zuordnung, wie die jeweiligen Daten, wird davon ausgegangen, dass er keinen Zugriff benötigt und der Zugriff daher verweigert.
Ein frei verfügbares Betriebssystem, welches das Modell der obligatorischen Zugriffssteuerung einsetzt, ist beispielsweise SE Linux [Na09].
Rollenbasierte Zugriffssteuerung
Bei der rollenbasierten Zugriffssteuerung werden Organisationsrichtlinien und -abläufe in ein Zugriffsmodell übersetzt. Dabei werden einzelnen Usern oder Systemen bestimmte (Organisations-)Rollen zugeordnet. Der Zugriff auf Daten hängt dabei von der jeweiligen Rolle des Zugreifenden ab. Die Berechtigung wird bei jedem Zugriffsversuch überprüft und dann genehmigt oder abgewiesen.
Bei den hier eingesetzten Rollen handelt es sich nicht um Gruppen im Sinne der Eigner-definierten Zugriffssteuerung, sondern um Rollen innerhalb des jeweiligen Geschäftsprozesses bzw. einer Organisationseinheit. So kann ein User eine Rolle haben, die ihm aus einer Anwendung heraus Zugriff auf einen Datensatz gestattet und aus einer anderen Anwendung nicht mehr, obwohl es sich um denselben Datensatz handelt. Wichtig ist dabei immer die Betrachtung des aktuellen Zwecks des Zugriffes.
Die Implementierung rollenbasierter Zugriffssteuerungen ist daher auch komplexer als die der Eigner-definierten Zugriffssteuerung.
Passwortsicherheit
Wie bereits in Lektion 3 beschrieben, hat die sichere Speicherung von Passwörtern eine hohe Priorität und sollte in einer entsprechend sicheren Architektur erfolgen. Zusätzlich zur technischen Sicherheit ist eine entsprechende Passwortkomplexität von besonderer Relevanz. Ein noch so effizient abgesicherter Passwortspeicher verliert an Bedeutung, wenn das darin gespeicherte Passwort selbst unsicher ist.
Ein unsicheres Passwort hat entweder:
- eine zu geringe Komplexität und kann daher durch Bruteforce- oder Hash-Kollisions-Angriffe (siehe auch Kapitel 3.7.1 und 3.7.3) gefunden werden, oder
- kann durch Social Engineering (siehe auch Kapitel 2.3) herausgefunden werden (z.B.: Name des Kindes mit Jahreszahl, Anfangsbuchstaben des Titels des Lieblingsliedes, usw.).
Die Komplexität eines Passwortes ergibt sich aus der Entropie – also den möglichen unterschiedlichen Kombinationen bzw. dem Keyspace (siehe Kapitel 3.1.4). Daraus und an der Anzahl an Passwörtern, welche pro Sekunde geprüft werden können, ergibt sich dann wiederum die Dauer, in welcher das Passwort durch Ausprobieren (Bruteforce-Angriff) gefunden werden kann.
Für die Komplexität von Passwörter galt lange eine bestimmte Mindestlänge (meist 8 Zeichen) und eine Kombination aus den Merkmalen:
- Kleinbuchstaben,
- Großbuchstaben,
- Ziffern und
- Sonderzeichen
als ausreichender Schutz.
Beispielsweise ein Passwort „f9D22+P#“ mit 8 Zeichen und Erfüllung aller oben genannten Kriterien hat somit folgende Komplexität:
- 26 Kleinbuchstaben +
- 26 Großbuchstaben +
- 10 Ziffern +
- 36 Sonderzeichen (alle Sonderzeichen der deutschen Tastatur)
- = 98 Mögliche Zeichen pro Stelle.
- Bei 8 Zeichen sind das 98^8 Mögliche Passortkombinationen.
Ein Hochleistungs-PC, welcher 2.148.000.000 Passwörter in der Sekunde ausprobieren kann, benötigt somit durchschnittlich ca. 23 Tage um das Passwort herauszufinden.
Ein Problem solcher komplexen Passwörter ist, dass es für die meisten User schwierig ist, sie sich zu einzuprägen. Dadurch besteht ein erhöhtes Risiko, dass die Passwörter:
- vergessen werden,
- auf einem Zettel notiert werden,
- nicht ausreichend oft geändert werden oder
- nur minimal geändert werden – beispielsweise durch simple Variation einzelner Teile des Passwortes, wie einer Ziffer am Ende.
Aufgrund der oben genannten Schwächen und der dennoch geringen Entropie noch gut merkbarer Passwortlängen, können diese Passwortrichtlinien nicht mehr als Stand der Technik betrachtet werden. Eine wesentlich bessere Möglichkeit ist die Nutzung von zufälligen Wörtern aus dem Wörterbuch. [Ga17]
Bei der Nutzung von vier zufälligen Wörtern aus dem Wörterbuch (kein Satz, sondern tatsächlich zufällig gewählte Wörter), ergibt sich bei Nutzung der 100.000 unterschiedlichen Wörter des Österreichischen Wörterbuchs [AF20] folgende Komplexität:
- 100.000 mögliche Wörter pro „Stelle“ (ein Wort ist somit eine Stelle).
- Bei 5 Wörtern sind das 100.000^4 Mögliche Passortkombinationen.
Ein Hochleistungs-PC (der selbe PC wie im ersten Beispiel), welcher 2.148.000.000 Passwörter in der Sekunde ausprobieren kann, benötigt somit durchschnittlich ca. 738 Jahre um das Passwort herauszufinden.
Ein Beispiel für ein Passwort aus 4 unzusammenhängenden Wörtern aus dem deutschen Duden ist: „Dachs faul logisch Gerät“.
Das Passwort weißt somit eine wesentlich höhere Entropie auf und ist für einen Menschen gleichzeitig leichter merkbar.
Leider ist diese Form der Passwörter in vielen Systemen noch nicht implementiert und es werden noch die veralteten Komplexitätsmerkmale des ersten Beispiels abgerufen. Diese Hürde kann ganz einfach überwunden werden, indem am Ende des Passworts eine Ziffer und ein Sonderzeichen gestellt werden. Da diese keine wirkliche Relevanz für die genannte Passwortsicherheit haben, können hier auch Zeichen genutzt werden, die schnell zu tippen sind. Das oben genannte Passwort könnte damit dann einfach „Dachs faul logisch Gerät 9+“ lauten.
Zertifikate
Zertifikate dienen der Feststellung der Identitäten von Personen und Systemen auf digitalem Wege. Ein Zertifikat ist ein digitales Dokument, indem bestimmte Daten angegeben sind, welche eine Person oder ein System und optional auch zugehörige Eigenschaften identifizieren. Zertifikate sind wesentliche Bestandteile von Public-Key-Systemen und enthalten zusätzlich den jeweiligen Public-Key des Zertifikatsinhabers (siehe auch Lektion 3.4).
Um die Echtheit eines Zertifikats zu bestätigen, kann dieses von anderen Stellen signiert werden. Diese Stellen werden als Zertifizierungsstellen (CA: Certification Authority) bezeichnet. Die Signatur erfolgt dabei, wie in Lektion 3.4 beschrieben, durch hashen des Zertifikates und Verschlüsselung des Hashwertes durch den privaten Schlüssel der Zertifizierungsstelle. Da der öffentliche Schlüssel – wiederum durch das Zertifikat der Zertifizierungsstelle – bekannt ist, kann der Hashwert korrekt entschlüsselt, und die Signatur damit als gültig erkannt, werden.
Ob diese Echtheitsbestätigungen nun hierarchisch erfolgen (Public-Key-Infrastruktur, Lektion 4.3.1), oder über ein dezentral verteiltes Vertrauensmodell (Web of Trust, Lektion 4.3.2) ist von der jeweiligen Implementierung abhängig. Derzeit sind beide Modellvarianten im Einsatz und finden ihre Anwendung in einer Vielzahl von Systemen. Die Zertifikate der behördlich akzeptierten digitalen Signaturen basieren derzeit auf dem hierarchischen Modell der Public-Key-Infrastruktur.
Ein Zertifikat ist mit einem Ausweisdokument vergleichbar. Auf dem Ausweis befinden sich die Daten der Person und ein Verweis auf den Aussteller. Durch Sicherheitsmerkmale am Dokument (Wasserzeichen, Silberstreifen,…) wird dabei die Echtheitsprüfung ermöglicht. Der Aussteller (z.B. eine Behörde) bestätigt damit die Identität des Inhabers (z.B. Personalausweis) und gegebenenfalls auch bestimmte durch das Dokument erlaubte Tätigkeiten (z.B. Führerschein).
Die Echtheit eines Zertifikates kann von der jeweiligen Zertifizierungsstelle auch wieder zurückgezogen werden. Zu diesem Zweck werden Zertifikats-Sperrlisten (CRL: Certificate Revocation Lists) eingesetzt, welche Einträge der Seriennummern aller Zertifikate mit zurückgenommenen Echtheitsbestätigungen enthält. Die Sperrliste ist selbst wiederum von der jeweiligen Zertifizierungsstelle signiert, um ihre Echtheit zu bestätigen.
Der Aufbau und der mögliche Inhalt eines Zertifikates ist im X.509 Standard [Ne99] definiert. Ein entsprechendes Beispiel (das aktuelle Zertifikat des Online-Campus) ist in Abbildung 16 dargestellt.
Public-Key-Infrastruktur (PKI)
Bei der Public-Key-Infrastruktur (PKI) handelt es sich um ein hierarchisch aufgebautes System von Zertifizierungsstellen. Das bedeutet, dass jede Zertifizierungsstelle das in sie gesetzte Vertrauen an nachfolgende Stellen weiterverteilen kann, indem sie die zugehörigen Zertifikate signiert.
Daraus ergibt sich dann eine Hierarchie aus mehreren Zertifikaten, die bis zu einem Stammzertifikat rückverfolgt werden können sind. Durch das Vertrauen in das jeweilige Stammzertifikat wird auch den nachfolgenden Zertifikaten vertraut.
In den meisten Anwendungen, die PKI Zertifikate einsetzen (z.B. Internetbrowser für HTTPS Verbindungen), sind bereits einige gängige Stammzertifikate der großen Zertifizierungsstellen vorinstalliert. Es ist jedoch meist auch möglich weitere Stammzertifikate hinzuzufügen, denen dann ebenfalls vertraut wird. In Abbildung 17 ist die Hierarchie des Zertifikates des Online-Campus dargestellt. Die Stammzertifizierungsstelle ist in diesem Fall das Unternehmen Go Daddy.
Zusätzlich zu den Zertifizierungsstellen gibt es in der PKI noch weitere Instanzen, welche hautsächlich für den Zertifizierungsprozess verantwortlich sind. Die Hauptakteure der PKI sind:
- Zertifizierungsstelle (CA: Certification Authority),
- Registrierungsstelle (RA: Registration Authority) und
- Validierungsdienst (VA: Validation Authority)
Die Registrierungsstelle ist in der PKI dafür verantwortlich die Identität des Antragsstellers zu überprüfen und dies wiederum der Zertifizierungsstelle mitzuteilen. Die Validierungsstelle ist für die Gültigkeitsprüfung von bereits ausgestellten Zertifikaten verantwortlich. Sie verwaltet auch die Zertifikats-Sperrlisten und ihre Erreichbarkeit ist meist in einem Datenfeld in den Zertifikaten selbst angegeben.
Soll nun ein neues Zertifikat ausgestellt werden, muss folgender Zertifizierungsprozess durchlaufen werden:
- Der Antrag für das neue Zertifikat wird an die Registrierungsstelle (RA) geschickt
- Die Registrierungsstelle (RA) überprüft den Antrag und stellt sicher, dass es sich bei der Identität tatsächlich um die der antragstellenden Person oder des zugehörigen IT-Systems (z.B. bei einem Webserver-Zertifikat) handelt.
- Wenn die Registrierungsstelle die Identität bestätigen kann, sendet sie den Antrag weiter an die Zertifizierungsstelle (CA).
- Die Zertifizierungsstelle (CA) stellt nun das beantragte Zertifikat aus, generiert dafür einen privaten und einen öffentlichen Schlüssel und sendet diese an die antragsstellende Person.
Oft ist es auch möglich das Schlüsselpaar selbst zu generieren und dem Antrag nur den öffentlichen Schlüssel beizufügen. Dies ist für die Ausstellung des Zertifikates ausreichend, da der private Schlüssel für seine Signierung nicht benötigt wird (diese wird durch den privaten Schlüssel der CA durchgeführt). In diesem Fall ist zusätzlich sichergestellt, dass der private Schlüssel nur der antragsstellenden Person bekannt ist.
Gerade bei der Überprüfung durch die Registrierungsstelle gibt es unterschiedliche Qualitäten. Wird hier ungenau vorgegangen, kann dies zu Zertifikaten falscher Identitäten führen.
Web of Trust (WOT)
Das Modell des Web of Trust ist im Gegensatz zur PKI nicht hierarchisch, sondern dezentral aufgebaut. Es basiert auf einer dezentralen Vertrauensverteilung zwischen den Teilnehmern, ähnlich dem Freundes- und Bekanntenkreis einer Person. Die Schlüssel sind dabei nicht in einer hierarchischen Struktur zentral abrufbar und überprüfbar, sondern werden direkt von den Benutzern verwaltet. Jeder User hat seinen eigenen Schlüsselbund, wobei hier zwischen dem privaten und dem öffentlichen Schlüsselbund unterschieden wird.
Am privaten Schlüsselbund befinden sich die privaten Schlüssel des Users, mit denen Daten signiert und entschlüsselt werden können. Am öffentlichen Schlüsselbund befinden sich die eigenen öffentlichen Schlüssel, sowie die öffentlichen Schlüssel anderer User. Mit den öffentlichen Schlüsseln können Nachrichten verschlüsselt und Signaturen geprüft werden.
Die Vertrauensstufen werden über die öffentlichen Schlüssel der Teilnehmer ermittelt. Dazu gibt es im öffentlichen Schlüsselbund für jeden Schlüssel ein Key Legimitation Field, in dem der jeweilige Vertrauensgrad (Owner Trust) des Schlüssels angegeben wird.
Im WOT gibt es folgende Vertrauensgrade:
- unknown: Personen über die keine Informationen bekannt sind,
- not trusted: Personen denen nicht vertraut wird,
- marginal: Personen denen nicht voll vertraut wird,
- complete: Personen denen voll vertraut wird und
- ultimate: eigener öffentlicher Schlüssel.
Wer als vertrauenswürdig eingestuft wird, liegt somit beim jeweiligen Schlüsselbund Inhaber.
Die Vertrauensgrade können an andere User (z.B. über einen Schlüsselserver) weitergegeben werden, indem die jeweiligen Schlüssel durch den eigenen privaten Schlüssel signiert werden. Dies wird auch als indirekte Zertifizierung bezeichnet.
Ist dem User, der einen dritten Schlüssel signiert hat, im eigenen Schlüsselbund einem Vertrauensgrad zugewiesen, so erhält der von ihm signierte Schlüssel je nach eigener Einstellung denselben Vertrauensgrad oder niedriger. Zusätzlich kann definiert werden, wie viele signierte Schlüssel eines niedrigeren Vertrauensgrades notwendig sind, um die Vertrauensstufe um eine Stufe aufzuwerten. Die Standartwerte hierfür sind 3 signierte Schlüssel anderer User für die Aufwertung und ein signierter Schlüssel eines anderen Users für dieselbe Stufe.
Diese Abhängigkeiten sind in Abbildung 18 ersichtlich: Peter kennt sowohl Anna, als auch Christoph persönlich und hat daher ihre öffentlichen Schlüssel in seinem öffentlichen Schlüsselbund abgelegt. Christoph hat nur eine direkte Beziehung zu Anna, nicht aber zu Peter. Da sich Christophs öffentlicher Schlüssel im öffentlichen Schlüsselbund von Anna befindet, erkennt Peter sein Zertifikat als gültig an.
Web of Trust - Vertrauensnetzwerk
Die erste Implementierung des WOT war Pretty Good Privacy (PGP) [Sy15]. Es ist ein Softwarepaket, welches die Sicherstellung der Authentizität, Integrität und Vertraulichkeit von E-Mails sowie beliebiger Dateien ermöglicht. GnuPG [Gn15] ist die frei verfügbare Version, die unter der GNU General Public License [Fr07] steht. Ein möglicher Windows Client für GnuPG ist beispielsweise Gpg4win [In15b].
Neue Zertifikatsmodelle und Erweiterungen
Sowohl im Bereich des PKI, als auch im WOT Modell, gibt es mittlerweile einige bekannte Sicherheitslücken und Protokollfehler. Weiter ist gerade im PKI Modell die Rolle der CA enorm wichtig. Werden hier nur schlechte Identitätskontrollen bei der Ausstellung von Zertifikaten durchgeführt, kann es zu falschen validen Identitäten kommen. Im Bereich des WOT können beispielsweise die Schlüsselserver zum Generieren von SPAM-Versandlisten genutzt werden, da die zugehörigen E-Mailadressen der Zertifikate dort frei verfügbar sein müssen. Weiter sind über die WOT soziale Netzwerke der User analysierbar, da die Trustlevel und ihre Abhängigkeiten leicht analysiert werden können. [Br14]
Um diese Schwachstellen zu beseitigen wird bereits an möglichen neuen Protokollen und Erweiterungen geforscht. Den meisten Ansätzen gemein ist, die Abhängigkeit von einzelnen CA’s zu verringern. Fehler einer CA sollen möglichst auf Seite der Endanwendung (wie z.B. im Browser oder Mail Client) frühzeitig erkannt und angezeigt werden. [Br14]
Einer dieser neuen Ansätze ist die Software Perspectives [Ca15]. Dabei handelt es sich um eine Browsererweiterung, die jedes Zertifikat zusätzlich mit einem sogenannten Notary-Server abgleicht. Damit können beispielsweise Man-in-the-Middle Angriffe frühzeitig erkannt werden.
Weitere aktuelle Erweiterungen sind [Br14]:
- Pinning [EPS14],
- Certificate Transparency [LLK13],
- Microsoft SmartScreen [Mi15] und
- DANE [HVS12].
Angriffsvektoren der Access Control
Die Angriffsmethoden der Access Control sind sehr vielfältig und haben oft Angriffsvektoren der Kryptographie (Lektion 3.7) und Datenübertragung (Lektion 5.6), sowie Social Engineering (Lektion 2.3) als Grundlage. Dies trifft insbesondere auf Angriffe gegen die Integrität und Authentizität zu.
Dazu bereits behandelte Angriffsvektoren sind:
- Brute-Force Angriffe (Lektion 3.7.1),
- Phishing (Lektion 2.3.1) und
- Angriffe gegen Hashwerte (Lektion 3.7.3).
Eine weitere wichtige Angriffsmethode ist die des Pharming. Dabei wird die Anfrage eines Users auf einen bösartigen Server umgeleitet. Er glaubt sich sicher und gibt dann dort seine geheimen Daten ( wie z.B.: Zugangsdaten und Transaktionsdaten) preis. Beim Pharming handelt es sich daher um einen Man-in-the-Middle Angriff (siehe Lektion 5.6.3).
Wiederholungsaufgaben/Übungen
1 Was ist der Unterschied zwischen Identifikation, Authentifikation und Autorisation?
2 Was ist eine Zwei-Faktor-Authentifikation?
3 Welche drei Zugriffssteuerungsmodelle gibt es?
4 Erklären Sie das Modell der Eigner-definierten Zugriffssteuerung.
5 Was sind Zertifikate und die damit verbundenen Vertrauensmodelle?
6 Was bedeutet PKI und wer sind ihre Hauptakteure? Wie hängen diese Akteure zusammen?
7 Eine Passwortrichtlinie fordert ein Passwort, bestehend aus Kleinbuchstaben, Großbuchstaben und Ziffern mit einer Länge von 10 Zeichen. Wie wird die Komplexität des Passworts berechnet (wie viele mögliche Passwörter gibt es)?



